杂项
[TOC]
page coloring
系统在为进程分配内存空间时,是按照 virtual memory 分配的,然后 virtual memory 会映射到不同的 physical memory,这样会导致一个问题,相邻的 virtual memory 会映射到不相邻的 physical memory 中,然后在缓存到 cache 中时,相邻的 virtual memory 会映射到同一个 cache line,从而导致局部性降低,性能损失。
Page coloring 则是将 physical memory 分为不同的 color,不同 color 的 physical memory 缓存到不同的 cache line,然后映射到 virtual memory 时,virtual memory 也有不同的 color。这样就不存在相邻的 virtual memory 缓存到 cache 时在同一个 cache line。(很有意思,现在没能完全理解。和组相联映射有什么关系?4k 页和 16k 页和这个又有什么关系?)

程序优化技术
优化程序性能的基本策略:
(1)高级设计。为遇到的问题选择合适的算法和数据结构。
(2)基本编码原则。避免限制优化的因素,这样就能产生高效的代码。
消除连续的函数调用。在可能时,将计算移到循环外。考虑有选择地妥协程序的模块性以获得更大的效率。
消除不必要的内存引用。引入临时变量来保存中间结果。只有在最后的值计算出来时,才将结果存放到数组或全局变量中。
(3)低级优化。结构化代码以利用硬件功能。
展开循环,降低开销,并且使得进一步的优化成为可能。
通过使用多个累积变量和重新结合等技术,找到方法提高指令级并行。
用功能性的风格重新些条件操作,使得编译采用条件数据传送而不是条件跳转。
最后,由于优化之后的代码结构发生变化,每次优化都需要对代码进行测试,以此保证这个过程没有引入新的错误。
(4)程序剖析工具:
gcc -Og -pg xxx.c -o xxx
./xxx file.txt
gprof xxx
代理
代理(Proxy)是一种特殊的网络服务,允许一个网络终端(一般为客户端)通过这个服务与另一个网络终端(一般为服务器)进行非直接的连接。一般认为代理服务有利于保障网络终端的隐私或安全,防止攻击。
代理服务器提供代理服务。一个完整的代理请求过程为:客户端首先与代理服务器创建连接,接着根据代理服务器所使用的代理协议,请求对目标服务器创建连接、或者获得目标服务器的指定资源。在后一种情况中,代理服务器可能对目标服务器的资源下载至本地缓存,如果客户端所要获取的资源在代理服务器的缓存之中,则代理服务器并不会向目标服务器发送请求,而是直接传回已缓存的资源。一些代理协议允许代理服务器改变客户端的原始请求、目标服务器的原始响应,以满足代理协议的需要。代理服务器的选项和设置在计算机程序中,通常包括一个“防火墙”,允许用户输入代理地址,它会遮盖他们的网络活动,可以允许绕过互联网过滤实现网络访问。
代理服务器的基本行为就是接收客户端发送的请求后转发给其他服务器。代理不改变请求 URI,并不会直接发送给前方持有资源的目标服务器。
HTTP/HTTPS/SOCKS 代理指的是客户端连接代理服务器的协议,指客户端和代理服务器之间交互的协议。
Socks
SOCKS 是一种网络传输协议,主要用于客户端与外网服务器之间通讯的中间传递。SOCKS 工作在比 HTTP 代理更低的层次:SOCKS 使用握手协议来通知代理软件其客户端试图进行的 SOCKS 连接,然后尽可能透明地进行操作,而常规代理可能会解释和重写报头(例如,使用另一种底层协议,例如 FTP;然而,HTTP 代理只是将 HTTP 请求转发到所需的 HTTP 服务器)。虽然 HTTP 代理有不同的使用模式,HTTP CONNECT 方法允许转发 TCP 连接;然而,SOCKS 代理还可以转发 UDP 流量(仅 SOCKS5),而 HTTP 代理不能。
fpu, xmm, mmx 之间的关系和区别
(1) x87 fpu 浮点部分,有 8 个浮点寄存器,st(i),top 指针指向当前使用的寄存器。


(2) xmm 支持 simd 指令的技术。8 个 xmm 寄存器,和 fpu 一样的组织形式。
The MMX state is aliased to the x87 FPU state. No new states or modes have been added to IA-32 architecture to support the MMX technology. The same floating-point instructions that save and restore the x87 FPU state also handle the MMX state.


(3) sse extensions(The streaming SIMD extensions)
和 mmx 一样,也是 simd 扩展,但是 sse 是 128-bit 扩展。在 32-bit 模式下有 8 个 128-bit 寄存器,也称作 xmm 寄存器,在 64-bit 模式下有 16 个 128-bit 寄存器。
32-bit 的 mxcsr 寄存器为 xmm 寄存器提供控制和状态位。

mmap
mmap, munmap - map or unmap files or devices into memory
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);
int munmap(void *addr, size_t length);
mmap() creates a new mapping in the virtual address space of the calling process for a device, file and etc, so process can operate the device use va, rather than use read and write. The starting address for the new mapping is specified in addr. The length argument specifies the length of the mapping (which must be greater than 0).
If addr is NULL, then the kernel chooses the (page-aligned) address at which to create the mapping. If addr is not NULL, then the kernel takes it as a hint about where to place the mapping;
The contents of a file mapping are initialized using length bytes starting at offset offset in the file (or other object) referred to by the file descriptor fd.
The prot argument describes the desired memory protection of the mapping.
The flags argument determines whether updates to the mapping are visible to other processes mapping the same region, and whether updates are carried through to the underlying file.
The munmap() system call deletes the mappings for the specified address range, and causes further references to addresses within the range to generate invalid memory references. If the process has modified the memory and has it mapped MAP_SHARED, the modifications should first be written to the file.
#include <> and #include "bar"
Usually, the #include <xxx> makes it look into system folders first, like /usr/local/include, /usr/include, the #include "xxx" makes it look into the current or custom folders first.
在文件首尾的地方添加
#ifndef _XXXXXX_H_
#define _XXXXXX_H_
....
#endif
用以确保声明只被 #include 一次。可以定义一个头文件,引用项目所有的头文件,然后其他的 .c 文件只需要引用这个头文件就可以。
对于自定义的头文件,如果需要引用,需要给 gcc 加上 -I 参数,设置头文件所在的目录。
用 #include 引用头文件时,编译器在预处理时会将头文件在引用的地方展开。
交叉编译
在 x86 机器上编译 x86 的可执行文件叫本地编译, 即在当前编译平台下,编译出来的程序只能放到当前平台下运行。
交叉编译可以理解为,在当前编译平台下,编译出来的程序能运行在不同体系结构的机器上,但是编译平台本身却不能运行该程序。比如,我们在 x86 平台上,编译能运行在 loongarch 机器的程序,编译得到的可执行文件在 x86 平台上是不能运行的,必须放到 loongarch 机器上才能运行。
ioctl
NAME
ioctl - control device
SYNOPSIS
#include <sys/ioctl.h>
int ioctl(int fd, unsigned long request, ...);
DESCRIPTION
The ioctl() system call manipulates the underlying device parameters of special files. In particular, many operating characteristics of character special files (e.g., terminals) may be controlled with ioctl() requests. The argument fd must be an open file descriptor.
The second argument is a device-dependent request code. The third argument is an untyped pointer to memory. It's traditionally char *argp (from the days before void * was valid C), and will be so named for this discussion.
An ioctl() request has encoded in it whether the argument is an in parameter or out parameter, and the size of the argument argp in bytes. Macros and defines used in specifying an ioctl() request are located in the file <sys/ioctl.h>.
C 语言中结构体成员变量前的点的作用
结构体中成员变量前的点: 结构体成员指定初始化
(1)该结构体要先定义;
(2)一个成员变量赋值完后用逗号而不是分号;
(3)初始化语句的元素以固定的顺序出现,和被初始化的数组或结构体中的元素顺序一样,这样可以不用按顺序初始化;
(4)C99 才开始支持的。
二进制兼容和源码兼容
二进制兼容:在升级库文件的时候,不必重新编译使用此库的可执行文件或其他库文件,并且程序的功能不被破坏。
源码兼容:在升级库文件的时候,不必修改使用此库的可执行文件或其他库文件的源代码,只需重新编译应用程序,即可使程序的功能不被破坏。
SMBIOS
SMBIOS is an industry-standard mechanism for low-level system software to export hardware configuration information to higher-level system management software.
Midware
Middleware is software that provides common services and capabilities to applications outside of what’s offered by the operating system. Data management, application services, messaging, authentication, and API management are all commonly handled by middleware.
Middleware helps developers build applications more efficiently. It acts like the connective tissue between applications, data, and users.
Middleware can support application environments that work smoothly and consistently across a highly distributed platform.
What Are the Components of a Linux Distribution
-
Display Server or Windows System
A display server is the responsible software about drawing the graphical user interface on the screen. From icons to windows and menus, every graphical thing you see on the screen is done by a display server (known also as windows system).
-
DMs are used to show the welcome screen after the boot loader and start desktop sessions as a connection with the X display server.
-
Daemons are programs that run in the background of the operating system instead of being normal applications with windows on the user interface. They run some specific jobs and processes that are needed by the operating system, like the network-manager daemon which allows you to connect to the network automatically when you login to your system.
The most famous daemon is called “systemd” which is the main daemon controlling the whole operating system jobs. It is the first process that is executed after loading the Linux kernel. Its job is simply to control other daemons and run them when needed at boot time or at any time you want, it controls all the services available on the operating system and it can turn it on or off or modify it when needed.
HT 总线
和 PCI 总线的区别在于 pci 总线是系统总线,用于连接外设,而 HT 总线速度更快,带宽更高,可以用来多核芯片的核间互联。
Super I/O
Super I/O 是主板上用来连接像 floppy-disk controller, parallel port, serial port, RTC 之类的低速设备的芯片。
extioi
extioi 是 LA 架构上的一个中断控制器。
系统启动过程
cpu 上电之后先从 rom 中加载 bios ,bios 完成的主要任务如下:
(1)上电自检(Power On Self Test, POST)指的是对硬件,如 CPU、主板、DRAM 等设备进行检测。POST 之后会有 Beep 声表示 POST 检查结果。一声简短的 beep 声意味着系统是 OK 的,两声 beep 则表示检查失败,错误码会显示在屏幕上;
(2)POST 之后初始化与启动相关的硬件,如磁盘、键盘控制器等;
(3)位 OS 创建一些参数,如 ACPI 表;
(4)选择引导设备,从设备中加载 bootloader。
bios 在完成对硬件进行检测,为 OS 准备相关参数之后,按照 BIOS 中设定的启动次序(Boot Sequence)逐一查找可启动设备,找到可启动的设备后,会把该设备第一个扇区(512 字节)—— MBR,的内容复制到内存的0x7c00处,然后检查内存的0x7dfe处(也就是从0x7c00开始的第 510 字节)开始的两个字节(510,511 字节,即 magic number)组成的数字是否是0xaa55。
512 bytes
+-----------------------+---------+--+
| | parti- | |
| boot loader | tion | | --> magic number(2 bytes)
| | table | |
+-----------------------+---------+--+
446 bytes / \
/ 64 bytes \
/ \
p1 p2 p3 p4(为啥有4个分区)
如果是,那么 bios 认为前 510 字节是一段可执行文件,于是 jump 到0x7c00处开始执行这段程序,即 MBR 开始执行;若不等于则转去尝试其他启动设备,如果没有启动设备满足要求则显示”NO ROM BASIC”然后死机。
qemu-img create -f qcow2 hello.img 10M
qemu-system-x86_64 hello.img

但 MBR 容量太小,放不下完整的 boot loader 代码,所以现在的 MBR 中的功能也从直接启动操作系统变为了启动 boot loader,一般是 grub。
kernel 要加载文件系统,也就是 / ,但是 / 是存储在磁盘中的,而读取磁盘需要驱动,而这时文件系统都没起来,驱动也没有,这就陷入一个死循环,所以 linux 做了一个初级的文件系统 initramfs ,initramfs 足够小,可以通过 bios 从磁盘加载到内存中,grub 会指定 initramfs 存放在内存的位置信息,这些信息放在一个单独的空页,并把这个页的地址提供给内核,内核根据地址找到 initramfs ,再通过 initramfs 启动 / ,启动 / 之后再 chroot ,切换到 / 。
开机时会进入 bios ,bios 初始化硬件信息,并跳转到 bootloader ,也就是 grub ,在 grub 中可以加入 break=mount ,使得在之后的启动中进入 initramfs 的 shell ,而不是直接执行 initramfs 。
细节还需要补充。
16550A UART
One drawback of the earlier 8250 UARTs and 16450 UARTs was that interrupts were generated for each byte received. This generated high rates of interrupts as transfer speeds increased. More critically, with only a 1-byte buffer there is a genuine risk that a received byte will be overwritten if interrupt service delays occur. To overcome these shortcomings, the 16550 series UARTs incorporated a 16-byte FIFO buffer with a programmable interrupt trigger of 1, 4, 8, or 14 bytes.
QEMU 虚拟机热迁移
虚拟机在运行过程中透明的从源宿主机迁移到目的宿主机。QEMU 中的 migration 子目录负责这部分工作,通过每个设备中有一个 VMStateDesrciption 的结构记录了热迁移过程中需要的迁移数据及相关回调函数。
同步与异步
所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回。按照这个定义,其实绝大多数函数都是同步调用(例如 sin, isdigit 等)。但是一般而言,我们在说同步、异步的时候,特指那些需要其他部件协作或者需要一定时间完成的任务。
同步,可以理解为在执行完一个函数或方法之后,一直等待系统返回值或消息,这时进程是出于阻塞的,只有接收到返回的值或消息后才往下执行其他的命令。
异步的概念和同步相对。当一个异步过程调用发出后,调用者不能立刻得到结果。由另外的并行进程执行这段代码,处理完这个调用的部件在完成后,通过状态、通知和回调来通知调用者。
异步,执行完函数或方法后,不必阻塞性地等待返回值或消息,只需要向系统委托一个异步过程,那么当系统接收到返回值或消息时,系统会自动触发委托的异步过程,从而完成一个完整的流程。
虚拟文件系统
在 Linux 中,普通文件、目录、字符设备、块设备、套接字等都以文件被对待;他们具体的类型及其操作不同,但需要向上层提供统一的操作接口。
虚拟文件系统 (VFS) 就是 Linux 内核中文件系统的抽象层,向上给用户空间程序提供文件系统操作接口;向下允许不同类型的文件系统共存,这些文件系统通过 VFS 结构封装向上提供统一操作接口。
通过虚拟文件系统,程序可以利用标准 Linux 文件系统调用在不同的文件系统中进行交互和操作。
_init and _initdata in kernle
These macros are used to mark some functions or initialized data (doesn’t apply to uninitialized data) as `initialization’ functions. The kernel can take this as hint that the function is used only during the initialization phase and free up used memory resources after.
exception_table_entry
/*
* The exception table consists of pairs of addresses: the first is the
* address of an instruction that is allowed to fault, and the second is
* the address at which the program should continue. No registers are
* modified, so it is entirely up to the continuation code to figure out
* what to do.
*
* All the routines below use bits of fixup code that are out of line
* with the main instruction path. This means when everything is well,
* we don't even have to jump over them. Further, they do not intrude
* on our cache or tlb entries.
*/
struct exception_table_entry
{
unsigned long insn, fixup;
};
start_kernel
| -- sort_main_extable
| -- sort_extable
void __init sort_main_extable(void)
{
if (main_extable_sort_needed && __stop___ex_table > __start___ex_table) {
pr_notice("Sorting __ex_table...\n");
sort_extable(__start___ex_table, __stop___ex_table);
}
}
void sort_extable(struct exception_table_entry *start,
struct exception_table_entry *finish)
{
sort(start, finish - start, sizeof(struct exception_table_entry),
cmp_ex_sort, swap_ex);
}
实模式与保护模式之间的切换
Seabios 中有实现两者是怎样切换的,而 Seabios.md 中详细分析了其实现。
守护进程
Linux Daemon(守护进程)是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。它不需要用户输入就能运行而且提供某种服务,不是对整个系统就是对某个用户程序提供服务。Linux 系统的大多数服务器就是通过守护进程实现的。常见的守护进程包括系统日志进程 syslogd、 web 服务器 httpd、邮件服务器 sendmail 和数据库服务器 mysqld 等。
守护进程一般在系统启动时开始运行,除非强行终止,否则直到系统关机都保持运行。守护进程经常以超级用户(root)权限运行,因为它们要使用特殊的端口(1-1024)或访问某些特殊的资源。
一个守护进程的父进程是 init 进程,因为它真正的父进程在 fork 出子进程后就先于子进程 exit 退出了,所以它是一个由 init 继承的孤儿进程。守护进程是非交互式程序,没有控制终端,所以任何输出,无论是向标准输出设备 stdout 还是标准出错设备 stderr 的输出都需要特殊处理。
守护进程的名称通常以 d 结尾,比如 sshd、xinetd、crond 等
sockets
A network socket is a software structure within a network node of a computer network that serves as an endpoint for sending and receiving data across the network. The structure and properties of a socket are defined by an application programming interface (API) for the networking architecture. Sockets are created only during the lifetime of a process of an application running in the node.
边沿触发和电平触发
边沿触发分上升沿触发和下降沿触发,简单说就是电平变化那一瞬间进行触发。 电平触发也有高电平触发、低电平触发,一般都是低电平触发。如果是低电平触发,那么在低电平时间内中断一直有效。
字符设备和块设备
系统中能够随机(不需要按顺序)访问固定大小数据片(chunks)的设备被称作块设备,这些数据片就称作块。最常见的块设备是硬盘,除此以外,还有软盘驱动器、CD-ROM 驱动器和闪存等等许多其他块设备。注意,它们都是以安装文件系统的方式使用的——这也是块设备的一般访问方式。
另一种基本的设备类型是字符设备。字符设备按照字符流的方式被有序访问,像串口和键盘就都属于字符设备。如果一个硬件设备是以字符流的方式被访问的话,那就应该将它归于字符设备;反过来,如果一个设备是随机(无序的)访问的,那么它就属于块设备。
SMM
SMM is a special-purpose operating mode provided for handling system-wide functions like power management, system hardware control, or proprietary OEM designed code. It is intended for use only by system firmware (BIOS or UEFI), not by applications software or general-purpose systems software. The main benefit of SMM is that it offers a distinct and easily isolated processor environment that operates transparently to the operating system or executive and software applications.
翻译过来就是 SMM 是一个特别的处理器工作模式,它运行在独立的空间里,具有自己独立的运行环境,与 real mode/protected mode/long mode 隔离,但是具有极高的权限。SMM 用来处理 power 管理、hardware 控制这些比较底层,比较紧急的事件。这些事件使用 SMI(System Management Interrupt) 来处理,因此进入了 SMI 处理程序也就是进入了 SMM ,SMI 是不可屏蔽的外部中断,并且不可重入(在 SMI 处理程序中不能响应另一个 SMI 请求)。
微内核和宏内核
微内核是将各种服务功能放到内核之外,自身仅仅是一个消息中转站,用于各种功能间的通讯,如 WindowNT。 宏内核是将所有服务功能集成于一身,使用时直接调用,如 Linux。 从理论上来看,微内核的思想更好些,微内核把系统分为各个小的功能块,降低了设计难度,系统的维护与修改也容易,但通信带来的效率损失是个问题。宏内核的功能块之间的耦合度太高造成修改与维护的代价太高,但其是直接调用,所以效率是比较高的。
What is a Unikernel
Normally, a hypervisor loads a Virtual Machine with a fully functional operating system, like some flavor of Linux, Windows, or one of the BSDs. These operating systems were designed to be run on hardware, so they have all the complexity needed for a variety of hardware drivers from an assortment of vendors with different design concepts. These operating systems are also intended to be multi-user, multi-process, and multi-purpose. They are designed to be everything for everyone, so they are necessarily complex and large.
A Unikernel, on the other hand, is (generally) single-purpose. It is not designed to run on hardware, and so lacks the bloat and complexity of drivers. It is not meant to be multi-user or multi-process, so it can focus on creating a single thread of code which runs one application, and one application only. Most are not multi-purpose, as the target is to create a single payload that a particular instance will execute (OSv is an exception). Thanks to this single-minded design, the Unikernel is small, lightweight, and quick.
kernel control path
A kernel control path is the sequence of instructions executed by a kernel to handle a system call, an interrupt or an exception.
The sequence of instructions executed in Kernel Mode to handle a kernel request is denoted as kernel control path : when a User Mode process issues a system call request, for instance, the first instructions of the corresponding kernel control path are those included in the initial part of the system_call( function, while the last instructions are those included in the ret_from_sys_call() function.
总结来说,就是 kernel 中处理 system call, interrupt 和 exception 的程序,一般以 system_call() 开始,以 ret_from_sys_call()结束。
ASCII

ret_from_fork
当执行中断或异常的处理程序后需要返回到原来的进程,在返回前还需要处理以下几件事:
-
并发执行的内核控制路径数(kernel control path)
如果只有一个,CPU 必须切换回用户模式。
-
待处理进程切换请求
如果有任何请求,内核必须进行进程调度;否则,控制权返回到当前进程。
-
待处理信号
如果一个信号被发送到当前进程,它必须被处理。
ret_from_fork 就是终止 fork(), vfork() 和 clone() 系统调用的。类似的函数还有
ret_from_exception:终止除了 0x80 异常外的所有异常处理程序。
ret_from_intr:终止中断处理程序
ret_from_sys_call:终止所有的系统调用处理程序。
下面是处理流程。

Initially, the ebx register stores the address of the descriptor of the process being replaced by the child (usually the parent’s process descriptor); this value is passed to the schedule_tail() function as a parameter. When that function returns, ebx is reloaded with the current’s process descriptor address. Then the ret_from_fork() function checks the value of the ptrace field of the current (at offset 24 of the process descriptor). If the field is not null, the fork( ), vfork( ), or clone( ) system call is traced, so the syscall_trace( ) function is invoked to notify the debugging process.
CFS
The Completely Fair Scheduler (CFS) is a default process scheduler of the tasks of the SCHED_NORMAL class (i.e., tasks that have no real-time execution constraints). It handles CPU resource allocation for executing processes, and aims to maximize overall CPU utilization while also maximizing interactive performance.
runqueue
The run queue may contain priority values for each process, which will be used by the scheduler to determine which process to run next. To ensure each program has a fair share of resources, each one is run for some time period (quantum) before it is paused and placed back into the run queue. When a program is stopped to let another run, the program with the highest priority in the run queue is then allowed to execute.
Processes are also removed from the run queue when they ask to sleep, are waiting on a resource to become available, or have been terminated.
Each CPU in the system is given a run queue, which maintains both an active and expired array of processes. Each array contains 140 (one for each priority level) pointers to doubly linked lists, which in turn reference all processes with the given priority. The scheduler selects the next process from the active array with highest priority.
watchdog
The Linux kernel can reset the system if serious problems are detected. This can be implemented via special watchdog hardware, or via a slightly less reliable software-only watchdog inside the kernel. Either way, there needs to be a daemon that tells the kernel the system is working fine. If the daemon stops doing that, the system is reset.
watchdog is such a daemon. It opens /dev/watchdog, and keeps writing to it often enough to keep the kernel from resetting, at least once per minute. Each write delays the reboot time another minute. After a minute of inactivity the watchdog hardware will cause the reset. In the case of the software watchdog the ability to reboot will depend on the state of the machines and interrupts.
LWP
轻量级进程(LWP)是建立在内核之上并由内核支持的用户线程,它是内核线程的高度抽象,每一个轻量级进程都与一个特定的内核线程关联。内核线程只能由内核管理并像普通进程一样被调度。
轻量级进程由 clone()系统调用创建,参数是 CLONE_VM,即与父进程是共享进程地址空间和系统资源。
与普通进程区别:LWP 只有一个最小的执行上下文和调度程序所需的统计信息。
- 处理器竞争:因与特定内核线程关联,因此可以在全系统范围内竞争处理器资源
- 使用资源:与父进程共享进程地址空间
- 调度:像普通进程一样调度
用户线程
用户线程是完全建立在用户空间的线程库,用户线程的创建、调度、同步和销毁全又库函数在用户空间完成,不需要内核的帮助。因此这种线程是极其低消耗和高效的。
LWP 虽然本质上属于用户线程,但 LWP 线程库是建立在内核之上的,LWP 的许多操作都要进行系统调用,因此效率不高。而这里的用户线程指的是完全建立在用户空间的线程库,用户线程的建立,同步,销毁,调度完全在用户空间完成,不需要内核的帮助。因此这种线程的操作是极其快速的且低消耗的。
GFP
Most of the memory allocation APIs use GFP flags to express how that memory should be allocated. The GFP acronym stands for “get free pages”, the underlying memory allocation function.
.macro
The commands .macro and .endm allow you to define macros that generate assembly output. For example, this definition specifies a macro sum that puts a sequence of numbers into memory:
.macro sum from=0, to=5
.long \from
.if \to-\from
sum "(\from+1)",\to
.endif
.endm
With that definition, `SUM 0,5’ is equivalent to this assembly input:
.long 0
.long 1
.long 2
.long 3
.long 4
.long 5
declaration and definition
Declaration of a variable or function simply declares that the variable or function exists somewhere in the program, but the memory is not allocated for them. The declaration of a variable or function serves an important role–it tells the program what its type is going to be. In case of function declarations, it also tells the program the arguments, their data types, the order of those arguments, and the return type of the function. So that’s all about the declaration.
Coming to the definition, when we define a variable or function, in addition to everything that a declaration does, it also allocates memory for that variable or function. Therefore, we can think of definition as a superset of the declaration (or declaration as a subset of definition).
A variable or function can be declared any number of times, but it can be defined only once.
extern
the extern keyword extends the function’s visibility to the whole program, the function can be used (called) anywhere in any of the files of the whole program, provided those files contain a declaration of the function.
CFI
On some architectures, exception handling must be managed with Call Frame Information directives. These directives are used in the assembly to direct exception handling. These directives are available on Linux on POWER, if, for any reason (portability of the code base, for example), the GCC generated exception handling information is not sufficient.
LPC
The Low Pin Count (LPC) bus is a computer bus used on IBM-compatible personal computers to connect low-bandwidth devices to the CPU, such as the BIOS ROM, “legacy” I/O devices, and Trusted Platform Module (TPM). “Legacy” I/O devices usually include serial and parallel ports, PS/2 keyboard, PS/2 mouse, and floppy disk controller.
PCH
The Platform Controller Hub (PCH) is a family of Intel’s single-chip chipsets. The PCH controls certain data paths and support functions used in conjunction with Intel CPUs.
GPIO
A general-purpose input/output (GPIO) is an uncommitted digital signal pin on an integrated circuit or electronic circuit board which may be used as an input or output, or both, and is controllable by the user at runtime.
IOMMU
IOMMU(input–output memory management unit) 有两大功能:控制设备 dma 地址映射到机器物理地址(DMA Remmaping),中断重映射(intremap)(可选)
第一个功能进一步解释是这样的,在没有 Iommu 的时候,设备通过 dma 可以访问到机器的全部的地址空间,这样会导致系统被攻击。当出现了 iommu 以后,iommu 通过控制每个设备 dma 地址到实际物理地址的映射转换,使得在一定的内核驱动框架下,用户态驱动能够完全操作某个设备 dma 和中断成为可能,同时保证安全性。
而 mmio 是设备 i/o 地址映射到内存,使得不用专门的 i/o 访存指令。
System.map
system.map 是保存内核的符号和该符号在内存中的地址映射关系的表。
control registor in X86
Control registers (CR0, CR1, CR2, CR3, and CR4; CR8 is available in 64-bit mode only.) determine operating mode of the processor and the characteristics of the currently executing task. These registers are 32 bits in all 32-bit modes and compatibility mode. In 64-bit mode, control registers are expanded to 64 bits.
- CR0 — Contains system control flags that control operating mode and states of the processor.
- CR1 — Reserved.
- CR2 — Contains the page-fault linear address (the linear address that caused a page fault).
- CR3 — Contains the physical address of the base of the paging-structure hierarchy and two flags (PCD and PWT). Only the most-significant bits (less the lower 12 bits) of the base address are specified; the lower 12 bits of the address are assumed to be 0. The first paging structure must thus be aligned to a page (4-KByte) boundary. The PCD and PWT flags control caching of that paging structure in the processor’s internal data caches (they do not control TLB caching of page-directory information).
- CR4 — Contains a group of flags that enable several architectural extensions, and indicate operating system or executive support for specific processor capabilities.
- CR8 — Provides read and write access to the Task Priority Register (TPR). It specifies the priority threshold value that operating systems use to control the priority class of external interrupts allowed to interrupt the processor.
this content can be find in Inter software developer’s manual: Volume 3 2.5.
TLB exceptions in mips
Three types of TLB exceptions can occur:
- TLB Refill occurs when there is no TLB entry that matches an attempted reference to a mapped address space.
- TLB Invalid occurs when a virtual address reference matches a TLB entry that is marked invalid.
- TLB Modified occurs when a store operation virtual address reference to memory matches a TLB entry which is marked valid but is not dirty (the entry is not writable).
Linux address space layout

Implicit Rules of Make
The important variables used by implicit rules are:
CC: Program for compiling C programs; defaultccCXX: Program for compiling C++ programs; defaultg++CFLAGS: Extra flags to give to the C compilerCXXFLAGS: Extra flags to give to the C++ compilerCPPFLAGS: Extra flags to give to the C preprocessorLDFLAGS: Extra flags to give to compilers when they are supposed to invoke the linker
用户栈
用户栈是属于用户进程空间的一块区域,用于保存用户进程子程序间的相互调用的参数、返回值等。
用户栈的栈底靠近进程空间的上边缘,但一般不会刚好对齐到边缘,出于安全考虑,会在栈底与进程上边缘之间插入一段随机大小的隔离区。这样,程序在每次运行时,栈的位置都不同,这样黑客就不大容易利用基于栈的安全漏洞来实施攻击。
当用户程序逐级调用函数时,用户栈从高地址向低地址方向扩展,每次增加一个栈帧,一个栈帧中存放的是函数的参数、返回地址和局部变量等,所以栈帧的长度是不定的。
内核栈
内核栈是属于操作系统空间的一块固定区域,可以用于保存中断现场、保存操作系统子程序间相互调用的参数、返回值等。
用户栈和内核栈的区别
内核在创建进程(进程这个概念是经典的操作系统参考书中用到的,其实内核源码中没有 thread 这个数据结构,都是 task 数据结构)的时候,需要创建 task_struct ,同时也会创建相应的堆栈。每个进程会有两个栈,一个用户栈,存在于用户空间,一个内核栈,存在于内核空间。当进程在用户空间运行时,cpu 堆栈指针寄存器(sp)里面的内容是用户堆栈地址,使用用户栈;当进程因为中断或者系统调用而陷入内核态执行时,sp 里面的内容是内核栈空间地址,使用内核栈。
进程陷入内核态后,先把用户态堆栈的地址保存在内核栈之中,然后设置 sp 的内容为内核栈的地址,这样就完成了用户栈向内核栈的转换;当进程从内核态恢复到用户态执行时,在内核态执行的最后将保存在内核栈里面的用户栈的地址恢复到堆栈指针寄存器即可。这样就实现了内核栈和用户栈的互转。
那么,我们知道从内核转到用户态时用户栈的地址是在陷入内核的时候保存在内核栈里面的,但是在陷入内核的时候,我们是如何知道内核栈的地址的呢?
关键在进程从用户态转到内核态的时候,进程的内核栈总是空的。这是因为当进程在用户态运行时,使用的是用户栈,当进程陷入到内核态时,内核栈保存进程在内核态运行的相关信息,但是一旦进程返回到用户态后,内核栈中保存的信息无效,会全部恢复,因此每次进程从用户态陷入内核的时候得到的内核栈都是空的。所以在进程陷入内核的时候,直接把内核栈的栈顶地址给堆栈指针寄存器就可以了。
x86 五级页表
内核为了支持不同的 CPU 体系架构,设计了五级分页模型。五级分页模型是为了兼容 X86-64 体系架构中的 5-Level Paging 分页模式。

五级分页每级命名分别为页全局目录(PGD)、页 4 级目录(P4D)、页上级目录(PUD)、页中间目录(PMD)、页表(PTE)。对应的相关宏定义命名如下:
#define PGDIR_SHIFT
#define P4D_SHIFT
#define PUD_SHIFT
#define PMD_SHIFT
#define PAGE_SHIFT
主缺页和次缺页
缺页中断可分为主缺页中断(Major Page Fault)和次缺页中断(Minor Page Fault),要从磁盘读取数据而产生的中断是主缺页中断;从内存中而不是直接从硬盘中读取数据而产生的中断是次缺页中断。
需要访存时内核先在 cache 中寻找数据,如果 cache miss,产生次缺页中断从内存中找,如果还没有发现的话就产生主缺页中断从硬盘读取。
系统调用
在内核中 int 0x80 表示系统调用,这是上层应用程序与内核进行交互通信的唯一接口。通过检查寄存器 %eax 中的值,内核会收到用户程序想要进行哪个系统调用的通知。
下面是部分系统调用(arch/x86/include/generated/asm/syscalls_64.h):
__SYSCALL(0, sys_read)
__SYSCALL(1, sys_write)
__SYSCALL(2, sys_open)
__SYSCALL(3, sys_close)
__SYSCALL(4, sys_newstat)
__SYSCALL(5, sys_newfstat)
__SYSCALL(6, sys_newlstat)
__SYSCALL(7, sys_poll)
__SYSCALL(8, sys_lseek)
__SYSCALL(9, sys_mmap)
__SYSCALL(10, sys_mprotect)
__SYSCALL(11, sys_munmap)
__SYSCALL(12, sys_brk)
Kernel Panic
起内核时经常会遇到这个问题:Kernel Panic (not syncing): attempted to kill init!
这是什么意思?
这个问题分为 3 个部分:
-
Kernel panic: A “kernel panic” is an unrecoverable error condition in, or detected by, the Linux kernel. It represents a situation where Linux literally finds it impossible to continue running, and stops dead in its tracks. (There is also a so-called “Oops” facility for recoverable errors.) Linux prints messages on the console and halts. Very often, the root cause of the problem will be indicated by some of these immediately-preceding messages.
-
not syncing: This part of the message indicates that the kernel was not in the middle of writing data to disk at the time the failure occurred. This is a supplemental piece of information that is not directly related to the panic message itself.
-
attempted to kill init: This is the situation that Linux actually detected, and this message is somewhat misleading. It actually means that “Process #1” either terminated or, just as likely, failed to start.
解释起来就是尝试杀死 init 进程。关于 init 进程的介绍可以看这里。
So, what can I do? In spite of the message referring to “kill init,” the most likely reason is that the process failed to start. Process #1 is an ordinary user process, running as root, and so it has the same basic requirements as any other process. Messages will usually be found in the log, immediately preceding the panic, which tell you more about exactly what went wrong.
For instance, a disk-driver that is needed to access the hard drive might have failed to load, because of a recent update to Linux that somehow went wrong. A menu of installed kernel versions usually appears briefly when you start the machine: try booting from the previous version of the Linux kernel.
Another distinct possibility is that the file system has become corrupt. In this case, you may need to try to boot the machine into a “recovery mode” (depending on your distro), or boot from a DVD or memory-stick. For instance, the startup menu on the installation disk for most Linux distros contains a “recovery” option which will attempt to check for and fix errors on the boot drive. Boot the system from that DVD and select this option. Any unexplained mis-behavior of a disk drive is also a strong indication that the drive may very soon need to be replaced.
用户态和内核态切换
-
系统调用 这是用户态进程主动要求切换到内核态的一种方式,用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作,比如
fork()实际上就是执行了一个创建新进程的系统调用。而系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现,例如 Linux 的int 0x80h中断。 系统调用实质上是一个中断,而汇编指令int(软中断)就可以实现用户态向内核态切换,iret实现内核态向用户态切换。 -
异常 当 CPU 在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
-
外围设备的中断 当外围设备完成用户请求的操作后,会向 CPU 发出相应的中断信号,这时 CPU 会暂停执行下一条即将要执行的指合转而去执行与中断信号对应的处理程序,如果先前执行的指合是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。 这 3 种方式是系统在运行时由用户态转到内核态的最主要方式,其中系统调用可以认为是用户进程主动发起的,异常和外围设备中断则是被动的。
而当 CPU 处于内核态,可以随意进入用户态。
系统态和用户态
You can tell if you’re in user-mode or kernel-mode from the privilege level set in the code-segment register (CS). Every instruction loaded into the CPU from the memory pointed to by the RIP(EIP) will read from the segment described in the global descriptor table (GDT) by the current code-segment descriptor. The lower two-bits of the code segment descriptor will determine the current privilege level that the code is executing at. When a syscall is made, which is typically done through a software interrupt, the CPU will check the current privilege-level, and if it’s in user-mode, will exchange the current code-segment descriptor for a kernel-level one as determined by the syscall’s software interrupt gate descriptor, as well as make a stack-switch and save the current flags, the user-level CS value and RIP value on this new kernel-level stack. When the syscall is complete, the user-mode CS value, flags, and instruction pointer (EIP or RIP) value are restored from the kernel-stack, and a stack-switch is made back to the current executing processes’ stack.
MMU
MMU 是 CPU 中的一个硬件单元,通常每个核有一个 MMU。MMU 由两部分组成:TLB(Translation Lookaside Buffer)和 table walk unit。
TLB 很熟悉了,就不再分析。主要介绍一下 table walk unit。
首先对于硬件 page table walk 的理解是有些问题的,即内核中有维护一套进程页表,为什么还要硬件来做呢?两者有何区别?第一个问题很好理解,效率嘛,第二个问题就是我们要分析的。
如果发生 TLB miss,就需要查找当前进程的 page table,接下来就是 table walk unit 的工作。而使用 table walk unit 硬件单元来查找 page table 的方式被称为 hardware TLB miss handling,通常被 CISC 架构的处理器(比如 IA-32)所采用。如果在 page table 中查找不到,出现 page fault,那么就会交由软件(操作系统)处理,之后就是我们熟悉的 PF。
好吧,从找到的资料看 page table walk 和我理解的内核的 4/5 级页表转换没有什么不同。但是依旧有一个问题,即 mmu 访问的这些 page table 是不是就是内核访问的 page table,都是存放在内存中的。
.bss 段清 0
根据 C 语法的规定,局部变量不设置初始值的时候,其初始值是不确定的,局部变量(不含静态局部变量)的存储位置位于栈上,具体位置不固定。未初始化的全局变量(和静态局部变量)存储在 .bss 段,初始值是 0,所以所有的进程在加载到内核执行时都要将 .bss 段清 0,而初始化国的全局变量和静态全局/局部变量存储在 .data 段。
早期的计算机存储设备是很贵的,而很多时候,数据段里的全局变量都是 0(或者没有初始值),那么存储这么多的 0 到目标文件里其实是没有必要的。所以为了节约空间,在生成目标文件的时候,就把没有初始值(实际就是 0)的数据段里的变量都放到 BSS 段里,这样目标文件就不需要那么大的体积里(节约磁盘空间)。只有当目标文件被载入的时候,加载器负责把 BSS 段清零(一个循环就可以搞定)。
RCU
RCU(Read-Copy Update)是数据同步的一种方式,在当前的 Linux 内核中发挥着重要的作用。RCU 主要针对的数据对象是链表,目的是提高遍历读取数据的效率,使用 RCU 机制读取数据的时候不对链表进行耗时的加锁操作。这样在同一时间可以有多个线程同时读取该链表,并且允许一个线程对链表进行修改(修改的时候,需要加锁)。RCU 适用于需要频繁的读取数据,而相应修改数据并不多的情景,例如在文件系统中,经常需要查找定位目录,而对目录的修改相对来说并不多,这就是 RCU 发挥作用的最佳场景。
register in X86
在 X86 架构中,对于不同寄存器的使用一定的约定:
- %rax 作为函数返回值使用;
- %rsp 栈指针寄存器,指向栈顶;
- %rdi,%rsi,%rdx,%rcx,%r8,%r9 用作函数参数,依次对应第 1 参数,第 2 参数等等;
-
%rbx,%rbp,%r12,%r13,%14,%15 用作数据存储,遵循被调用者使用规则,简单说就是随便用,调用子函数之前要备份它,以防被修改;
- %r10,%r11 用作数据存储,遵循调用者使用规则,简单说就是使用之前要先保存原值;
X86/64 的权限
- CPL(Current Privilege Level):当前的权限级别,CPL 的值放在 CS 寄存器的 Selector 域的 RPL,CS.Selector.RPL 与 SS 寄存器的 Selector.RPL 总是相等的,因此 SS.Selector.RPL 也是 CPL。
- DPL(Descriptor Privilege Level):DPL 存放在 Descriptor(包括 Segment Descriptor 和 Gate Descriptor)里的 DPL 域,它指示访问这些 segment 所需要的权限。
- RPL(Requested Privilege Level):和 CPL 一样。
当 CPL > DPL 时,表示当前运行的程序权限不足,无法访问 segment 或 gate。
x86 模式切换
x86 架构中 CPU 的模式众多,幸好手册给出了它们之间的关系。不过还有一个 Long Mode 是啥,好吧 intel 中 IA-32e 就是 Long Mode。

__randomize_layout
结构体随机化。不管是地址随机化,还是结构体随机化,其目的都是增强内核安全性。结构体随机化也是 GCC 编译器的一个重要特性,使能后将在编译时随机排布结构体中元素的顺序,从而使攻击者无法通过地址偏移进行攻击。
在内核中,结构体中存在函数指针的部分是攻击者重点关注的对象。因此,只存储函数指针的结构体,是默认开启结构体随机化的,如果不需要,需要添加 __no_randomize_layout 进行排除。另一方面,如果特定结构体希望主动开启保护,需要添加 __randomize_layout 标识。
结构体随机化后的差异:
-
既然已经开启了结构体随机化,在进行赋值或初始化时,就需要按照元素名称进行赋值,否则会出现非预期结果。
-
不要对开启了随机化的结构体指针或对象进行强制数据转换,因为内存排布是不可预测的。
-
涉及到远程调用的结构体,如果需要保证结构体内容的一致性,需要添加例外。
-
调试时,根据 dump 推算结构体内容将极为麻烦,因为每个版本、每个平台的布局都将不同。
-
部分以模块形式添加到内核中的驱动,为保持结构体一致性,在编译时需要采用与内核相同的随机数种子,这带来了极大的安全风险。
efi
EFI 系统分区(EFI system partition,ESP),是一个 FAT 或 FAT32 格式的磁盘分区。UEFI 固件可从 ESP 加载 EFI 启动程式或者 EFI 应用程序。
cpio
cpio 是 UNIX 操作系统的一个文件备份程序及文件格式。
The initial ramdisk needs to be unpacked by the kernel during boot, cpio is used because it is already implemented in kernel code.
All 2.6 Linux kernels contain a gzipped “cpio” format archive, which is extracted into rootfs when the kernel boots up. After extracting, the kernel checks to see if rootfs contains a file “init”, and if so it executes it as PID. If found, this init process is responsible for bringing the system the rest of the way up, including locating and mounting the real root device (if any). If rootfs does not contain an init program after the embedded cpio archive is extracted into it, the kernel will fall through to the older code to locate and mount a root partition, then exec some variant of /sbin/init out of that.
ACPI(建议浏览一下 ACPI手册)
Advanced Configuration and Power Interface (ACPI). Before the development of ACPI, operating systems (OS) primarily used BIOS (Basic Input/ Output System) interfaces for power management and device discovery and configuration.
ACPI can first be understood as an architecture-independent power management and configuration framework that forms a subsystem within the host OS. This framework establishes a hardware register set to define power states (sleep, hibernate, wake, etc). The hardware register set can accommodate operations on dedicated hardware and general purpose hardware.
The primary intention of the standard ACPI framework and the hardware register set is to enable power management and system configuration without directly calling firmware natively from the OS. ACPI serves as an interface layer between the system firmware (BIOS) and the OS.
There are 2 main parts to ACPI. The first part is the tables used by the OS for configuration during boot (these include things like how many CPUs, APIC details, NUMA memory ranges, etc). The second part is the run time ACPI environment, which consists of AML code (a platform independent OOP language that comes from the BIOS and devices) and the ACPI SMM (System Management Mode) code.
关键数据结构:
RSDT (Root System Description Table) is a data structure used in the ACPI programming interface. This table contains pointers to all the other System Description Tables. However there are many kinds of SDT. All the SDT may be split into two parts. One (the header) which is common to all the SDT and another (data) which is different for each table. RSDT contains 32-bit physical addresses, XSDT contains 64-bit physical addresses.
NUMA
NUMA 指的是针对某个 CPU,内存访问的距离和时间是不一样的。其解决了多 CPU 系统下共享 BUS 带来的性能问题(链接中的图很直观)。
NUMA 的特点是:被共享的内存物理上是分布式的,所有这些内存的集合就是全局地址空间。所以处理器访问这些内存的时间是不一样的,显然访问本地内存的速度要比访问全局共享内存或远程访问外地内存要快些。
initrd
Initrd ramdisk 或者 initrd 是指一个临时文件系统,它在启动阶段被 Linux 内核调用。initrd 主要用于当“根”文件系统被挂载之前,进行准备工作。
设备树(dt)
Device Tree 由一系列被命名的结点(node)和属性(property)组成,而结点本身可包含子结点。所谓属性, 其实就是成对出现的 name 和 value。在 Device Tree 中,可描述的信息包括(原先这些信息大多被 hard code 到 kernel 中):
- CPU 的数量和类别
- 内存基地址和大小
- 总线和桥
- 外设连接
- 中断控制器和中断使用情况
- GPIO 控制器和 GPIO 使用情况
- Clock 控制器和 Clock 使用情况
它基本上就是画一棵电路板上 CPU、总线、设备组成的树,Bootloader 会将这棵树传递给内核,然后内核可以识别这棵树, 并根据它展开出 Linux 内核中的 platform_device、i2c_client、spi_device 等设备,而这些设备用到的内存、IRQ 等资源, 也被传递给了内核,内核会将这些资源绑定给展开的相应的设备。
是否 Device Tree 要描述系统中的所有硬件信息?答案是否定的。基本上,那些可以动态探测到的设备是不需要描述的, 例如 USB device。不过对于 SOC 上的 usb hostcontroller,它是无法动态识别的,需要在 device tree 中描述。同样的道理, 在 computer system 中,PCI device 可以被动态探测到,不需要在 device tree 中描述,但是 PCI bridge 如果不能被探测,那么就需要描述之。
设备树和 ACPI 有什么关系?
关于设备树的知识看这个系列的文档就足够了:
BootMem 内存分配器
Bootmem is a boot-time physical memory allocator and configurator.
It is used early in the boot process before the page allocator is set up.
Bootmem is based on the most basic of allocators, a First Fit allocator which uses a bitmap to represent memory. If a bit is 1, the page is allocated and 0 if unallocated. To satisfy allocations of sizes smaller than a page, the allocator records the Page Frame Number (PFN) of the last allocation and the offset the allocation ended at. Subsequent small allocations are merged together and stored on the same page.
The information used by the bootmem allocator is represented by struct bootmem_data. An array to hold up to MAX_NUMNODES such structures is statically allocated and then it is discarded when the system initialization completes. Each entry in this array corresponds to a node with memory. For UMA systems only entry 0 is used.
The bootmem allocator is initialized during early architecture specific setup. Each architecture is required to supply a setup_arch function which, among other tasks, is responsible for acquiring the necessary parameters to initialise the boot memory allocator. These parameters define limits of usable physical memory:
- min_low_pfn - the lowest PFN that is available in the system
- max_low_pfn - the highest PFN that may be addressed by low memory (
ZONE_NORMAL) - max_pfn - the last PFN available to the system.
After those limits are determined, the init_bootmem or init_bootmem_node function should be called to initialize the bootmem allocator. The UMA case should use the init_bootmem function. It will initialize contig_page_data structure that represents the only memory node in the system. In the NUMA case the init_bootmem_node function should be called to initialize the bootmem allocator for each node.
Once the allocator is set up, it is possible to use either single node or NUMA variant of the allocation APIs.
现在的 bootmem 初始化是用的 memblock,详细看这个。
LoongArch 的 bootmem 似乎和 x86 的不一样,以下为 x86 的 bootmem 初始化过程。
bootmem_data 结构:
/**
* struct bootmem_data - per-node information used by the bootmem allocator
* @node_min_pfn: the starting physical address of the node's memory
* @node_low_pfn: the end physical address of the directly addressable memory
* @node_bootmem_map: is a bitmap pointer - the bits represent all physical
* memory pages (including holes) on the node.
* @last_end_off: the offset within the page of the end of the last allocation;
* if 0, the page used is full
* @hint_idx: the PFN of the page used with the last allocation;
* together with using this with the @last_end_offset field,
* a test can be made to see if allocations can be merged
* with the page used for the last allocation rather than
* using up a full new page.
* @list: list entry in the linked list ordered by the memory addresses
*/
typedef struct bootmem_data {
unsigned long node_min_pfn;
unsigned long node_low_pfn;
void *node_bootmem_map;
unsigned long last_end_off;
unsigned long hint_idx;
struct list_head list;
} bootmem_data_t;
bootmem 的需求是简单,因此使用 first fit 的方式。该分配器使用一个位图来管理页,位图中的 bit 数等于物理页数,bit 为 1,表示该页使用;bit 为 0,表示该页未用。在需要分配内存时,bootmem 逐位扫描位图,知道找到一个空间足够大的连续页的位置。这种每次分配都需要从头扫描的方式效率不高,因此内核初始化结束后就转用伙伴系统(连同 slab、slub 或 slob 分配器)。
NUMA 内存体系中,每个节点都要初始化一个 bootmem 分配器。
开始时位图中的 bit 都是 1,根据 BIOS 提供的可用内存区的列表,释放所有可用的内存页。由于 bootmem 需要一些内存页保存位图,必须先调用 reserve_bootmem 分配这些内存页(ACPI 数据和 SMP 启动时的配置也是通过 reserve_bootmem 保存的)。
在停用 bootmem 时,需要扫描位图释放每个未使用的页,释放完后,位图所在的页也要释放。
SWIOTLB
swiotlb 技术是一种纯软件的地址映射技术,主要为寻址能力受限的 DMA 提供软件上的地址映射。
在 64 位的系统中,如果为外设 DMA(部分外设 DMA 只支持 32 位)分配了超过其寻址能力的地址,那么该外设 DMA 无法使用该地址,这时就要使用 swiotlb。 swiotlb 维护了一块低地址的 buffer,该 buffer 的大小可以由 bootloader 通过 swiotlb 参数传递给内核,也可以使用默认值,默认值是 64M。如果给 DMA 分配的物理地址(这里记做 pa1)超过了其寻址能力,swiotlb 技术将从其 buffer 中分配同样大小的一块空间,给 DMA 使用,其物理地址记做 pa2,swiotlb 会维护 pa1 和 pa2 的映射关系。 这里有两个问题比较关键:
- 如何确保 swiotlb 维护的 buffer 在低地址呢? 尽可能早地分配该 buffer,在 ARM64 平台上在函数 mem_init 的一开始,就调用 swiotlb_init 做 swiotlb 的初始化,swiotlb_init 中就会分配所需要的 buffer;
- 如何维护 pa1 和 pa2 之间的映射?
- swiotlb 维护了一张 io_tlb_orig_addr 表,这张表维护了原始物理地址和 swiotlb 分配物理地址之间的映射关系。当 DMA 将数据写入 swiotlb 分配的物理地址后,一般会以中断的方式通知 CPU,CPU 在查看 DMA 写到内存的数据之前,需要先做一个 sync,该 sync 操作就会触发 swiotlb将数据拷贝到原始物理地址处,这样就保证了 CPU 能够看到正确的数据,不过显而易见,这种方法效率非常低下。
LSX 和 LASZ
龙芯架构下的向量扩展指令,其包括向量扩展(Loongson SIMD Extension, LSX)和高级向量扩展(Loongson Advanced SIMD Extension, LASX)。两个扩展部分均采用 SIMD 指令且功能基本一致,区别是 LSX 操作的向量位宽是 128 位,而 LASX 是 256 位。两者的关系类似与 xmm 和 mmx。
问题:
(1)正常在 LA 架构上运行 LA 内核是这样的,那如果在 LA 架构上运行 x86 内核是怎样的,BootLoader 直接传递 x86 内核的入口地址么。bios 要怎样把 LA 内核拉起来。
(2)源码要结合书一起看,而且要多找即本书,对比着看,因为有些内容,如 ACPI,bootmem 不是所有的书都会详细介绍。我用到的参考书有《基于龙芯的 Linux 内核探索解析》、《深入理解 LINUX 内核》、《深入 LINUX 内核架构》。
namespace
namespace 是 Linux 内核用来隔离内核资源的方式。通过 namespace 可以让一些进程只能看到与自己相关的一部分资源,而另外一些进程也只能看到与它们自己相关的资源,这两拨进程根本就感觉不到对方的存在。具体的实现方式是把一个或多个进程的相关资源指定在同一个 namespace 中。
Linux namespaces 是对全局系统资源的一种封装隔离,使得处于不同 namespace 的进程拥有独立的全局系统资源,改变一个 namespace 中的系统资源只会影响当前 namespace 里的进程,对其他 namespace 中的进程没有影响。也就是虚拟化的一种。
SPEC
spec 执行命令:
../00000003/gzip_base.O3.x86 input.source 60 1>input.source.out 2>input.source.err
../00000003/gzip_base.O3.x86 input.log 60 1>input.log.out 2>input.log.err
../00000003/gzip_base.O3.x86 input.graphic 60 1>input.graphic.out 2>input.graphic.err
../00000003/gzip_base.O3.x86 input.random 60 1>input.random.out 2>input.random.err
../00000003/gzip_base.O3.x86 input.program 60 1>input.program.out 2>input.program.err
../00000003/vpr_base.O3.x86 net.in arch.in place.out dum.out -nodisp -place_only -init_t 5 -exit_t 0.005 -alpha_t 0.9412 -inner_num 2 1>place_log.out 2>place_log.err
../00000003/vpr_base.O3.x86 net.in arch.in place.in route.out -nodisp -route_only -route_chan_width 15 -pres_fac_mult 2 -acc_fac 1 -first_iter_pres_fac 4 -initial_pres_fac 8 1>route_log.out 2>route_log.err
../00000003/cc1_base.O3.x86 166.i -o 166.s 1>166.out 2>166.err
../00000003/cc1_base.O3.x86 200.i -o 200.s 1>200.out 2>200.err
../00000003/cc1_base.O3.x86 expr.i -o expr.s 1>expr.out 2>expr.err
../00000003/cc1_base.O3.x86 integrate.i -o integrate.s 1>integrate.out 2>integrate.err
../00000003/cc1_base.O3.x86 scilab.i -o scilab.s 1>scilab.out 2>scilab.err
../00000003/mcf_base.O3.x86 inp.in 1>inp.out 2>inp.err
../00000003/crafty_base.O3.x86 <crafty.in 1>crafty.out 2>crafty.err
../00000003/parser_base.O3.x86 2.1.dict -batch <ref.in 1>ref.out 2>ref.err
../00000003/eon_base.O3.x86 chair.control.cook chair.camera chair.surfaces chair.cook.ppm ppm pixels_out.cook 1>cook_log.out 2>cook_log.err
../00000003/eon_base.O3.x86 chair.control.rushmeier chair.camera chair.surfaces chair.rushmeier.ppm ppm pixels_out.rushmeier 1>rushmeier_log.out 2>rushmeier_log.err
../00000003/eon_base.O3.x86 chair.control.kajiya chair.camera chair.surfaces chair.kajiya.ppm ppm pixels_out.kajiya 1>kajiya_log.out 2>kajiya_log.err
../00000003/perlbmk_base.O3.x86 -I./lib diffmail.pl 2 550 15 24 23 100 1>2.550.15.24.23.100.out 2>2.550.15.24.23.100.err
../00000003/perlbmk_base.O3.x86 -I. -I./lib makerand.pl 1>makerand.out 2>makerand.err
../00000003/perlbmk_base.O3.x86 -I./lib perfect.pl b 3 m 4 1>b.3.m.4.out 2>b.3.m.4.err
../00000003/perlbmk_base.O3.x86 -I./lib splitmail.pl 850 5 19 18 1500 1>850.5.19.18.1500.out 2>850.5.19.18.1500.err
../00000003/perlbmk_base.O3.x86 -I./lib splitmail.pl 704 12 26 16 836 1>704.12.26.16.836.out 2>704.12.26.16.836.err
../00000003/perlbmk_base.O3.x86 -I./lib splitmail.pl 535 13 25 24 1091 1>535.13.25.24.1091.out 2>535.13.25.24.1091.err
../00000003/perlbmk_base.O3.x86 -I./lib splitmail.pl 957 12 23 26 1014 1>957.12.23.26.1014.out 2>957.12.23.26.1014.err
../00000003/gap_base.O3.x86 -l ./ -q -m 192M <ref.in 1>ref.out 2>ref.err
../00000003/vortex_base.O3.x86 lendian1.raw 1>vortex1.out2 2>vortex1.err
../00000003/vortex_base.O3.x86 lendian2.raw 1>vortex2.out2 2>vortex2.err
../00000003/vortex_base.O3.x86 lendian3.raw 1>vortex3.out2 2>vortex3.err
../00000003/bzip2_base.O3.x86 input.source 58 1>input.source.out 2>input.source.err
../00000003/bzip2_base.O3.x86 input.graphic 58 1>input.graphic.out 2>input.graphic.err
../00000003/bzip2_base.O3.x86 input.program 58 1>input.program.out 2>input.program.err
../00000003/twolf_base.O3.x86 ref 1>ref.stdout 2>ref.err
../00000003/wupwise_base.O3.x86 1>wupwise.out 2>wupwise.err
../00000003/swim_base.O3.x86 <swim.in 1>swim.out 2>swim.err
../00000003/mgrid_base.O3.x86 <mgrid.in 1>mgrid.out 2>mgrid.err
../00000003/applu_base.O3.x86 <applu.in 1>applu.out 2>applu.err
../00000003/mesa_base.O3.x86 -frames 1000 -meshfile mesa.in -ppmfile mesa.ppm
../00000003/galgel_base.O3.x86 <galgel.in 1>galgel.out 2>galgel.err
../00000003/art_base.O3.x86 -scanfile c756hel.in -trainfile1 a10.img -trainfile2 hc.img -stride 2 -startx 110 -starty 200 -endx 160 -endy 240 -objects 10 1>ref.1.out 2>ref.1.err
../00000003/art_base.O3.x86 -scanfile c756hel.in -trainfile1 a10.img -trainfile2 hc.img -stride 2 -startx 470 -starty 140 -endx 520 -endy 180 -objects 10 1>ref.2.out 2>ref.2.err
../00000003/equake_base.O3.x86 <inp.in 1>inp.out 2>inp.err
../00000003/facerec_base.O3.x86 <ref.in 1>ref.out 2>ref.err
../00000003/ammp_base.O3.x86 <ammp.in 1>ammp.out 2>ammp.err
../00000003/lucas_base.O3.x86 <lucas2.in 1>lucas2.out 2>lucas2.err
../00000003/fma3d_base.O3.x86 1>fma3d.out 2>fma3d.err
../00000003/sixtrack_base.O3.x86 <inp.in 1>inp.out 2>inp.err
../00000003/apsi_base.O3.x86 1>apsi.out 2>apsi.err
AMP 和 SMP
AMP(Asymmetric Multi-processing)模式:AMP 模式的 RTOS 在各个 CPU 上均运行一个操作系统实例(这些操作实例不一定完全相同),各个操作系统拥有自己专用的内存,相互之间通过访问受限的共享内存进行通信。AMP 模式的操作系统结构需要用户参与系统资源的分配。这种类型的 RTOS 应用比较少,商用操作系统中仅有 Wind River 公司的 VxWorks 提供 AMP 模式的配置。
SMP(Symmetric Multi-processing)模式:SMP 模式的操作系统构架是多核处理器技术的一种变体,由一个操作系统实例控制所有处理器,所有处理器共享内存。与 AMP 模式中每个 CPU 上运行一个操作系统实例不同,SMP 模式系统中所有 CPU 的地位相同,共同运行一个操作系统实例,所有 CPU 共享系统内存和外设资源。相对于 AMP 模式,SMP 模式的操作系统具有可共享内存、较高的性能和功耗比、以及易实现负载均衡等优点,更能发挥发挥多核处理器的硬件优势。
chroot
chroot 命令用来在指定的根目录下运行指令。chroot,即 change root directory (更改 root 目录)。在 linux 系统中,系统默认的目录结构都是以/,即是以根 (root) 开始的。而在使用 chroot 之后,系统的目录结构将以指定的位置作为 / 位置。
What is Systemctl
Systemctl is a Linux command-line utility used to control and manage systemd and services. You can think of Systemctl as a control interface for Systemd init service, allowing you to communicate with systemd and perform operations.
new and malloc
https://zhuanlan.zhihu.com/p/338489910
硬中断和软中断
软中断是执行中断指令产生的,而硬中断是由外设引发的。
硬中断的中断号是由中断控制器提供的,软中断的中断号由指令直接指出,int 是软中断指令,无需使用中断控制器。硬中断是可屏蔽的,软中断不可屏蔽。硬中断处理程序要确保它能快速地完成任务,这样程序执行时才不会等待较长时间,称为上半部。软中断处理硬中断未完成的工作,是一种推后执行的机制,属于下半部。
中断嵌套
Linux 下硬中断是可以嵌套的,但是没有优先级的概念,也就是说任何一个新的中断都可以打断正在执行的中断,但同种中断除外。软中断不能嵌套,但相同类型的软中断可以在不同 CPU 上并行执行。
线程的同步和互斥
互斥:是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。但互斥无法限制访问者对资源的访问顺序,即访问是无序的。
同步:是指在互斥的基础上(大多数情况),通过其它机制实现访问者对资源的有序访问。
在大多数情况下,同步已经实现了互斥,特别是所有写入资源的情况必定是互斥的。少数情况是指可以允许多个访问者同时访问资源。
线程空间
| 线程私有 | 线程共享 |
|---|---|
| 局部变量 | 全局变量 |
| 函数的参数 | 堆上的数据 |
| TLS(线程局部存储,Thread Local Storage) | 函数中的静态变量 |
| 程序代码,任何线程都有权利读取并执行任何代码 | |
| 打开的文件,A 线程打开的文件可以由 B 线程读写 |
volatile 和 extern
- extern
- 当它与”C”一起连用。如:
extern "C" void fun(int a);这个告诉编译器在编译 fun 这个函数名时按 C 的规则去翻译相应的函数名,而不是 C++,因为 C++ 在翻译的时候会把这个 fun 名字变得面目全非,以支持 C++ 的函数重载。 - 全局变量不在文件的开头定义,有效的作用范围将只限于其定义处到文件结束。如果在定义点之前的函数想引用该全局变量,则应该在引用之前用关键字 extern 对该变量作“外部变量声明”,表示该变量是一个已经定义的外部变量。有了此声明,就可从“声明”处起,合法地使用该外部变量,然后在其他文件中定义。
- 如果整个工程由多个源文件组成,在一个源文件中想引用另外一个源文件中已经定义的外部变量,同样只需在引用变量的文件中用
extern关键字加以声明即可。
- 当它与”C”一起连用。如:
在编译的过程中编译器只需要知道数据类型和名字,以便知道如何使用它所以不会报错。一旦编译完成后,链接器会针对使用 extern 变量的模块,到包含的该变量的模块中生成的目标代码中找到此变量。即 extern关键字是在链接阶段起作用。
- volatile
确保编译器不会帮你对
volatile进行优化,让一切判断如你预期的执行。其在编译阶段起作用。
程序的各个区域
- 堆:堆允许程序在运行时动态地申请某个大小的内存。一般由程序员分配释放,如
malloc和free,需要仔细维护,不然会导致堆栈溢出; - 栈:由编译器自动分配释放,存放函数的参数值,局部变量等值;
- 静态存储区 :一定会存在且不会消失,这样的数据包括常量、常变量(const 变量)、静态变量、全局变量等;
- 常量存储区:常量占用内存,只读状态,决不可修改,常量字符串就是放在这里的。
static 的用法
- 用 static 修饰局部变量:使其变为静态存储方式(静态数据区),那么这个局部变量在函数执行完成之后不会被释放,而是继续保留在内存中。
- 用 static 修饰全局变量:使其只在本文件内部有效,而其他文件不可连接或引用该变量。
- 用 static 修饰函数:对函数的连接方式产生影响,使得函数只在本文件内部有效,对其他文件是不可见的(这一点在大工程中很重要很重要,避免很多麻烦,很常见)。这样的函数又叫作静态函数。使用静态函数的好处是,不用担心与其他文件的同名函数产生干扰,另外也是对函数本身的一种保护机制。
const 的用法
const 主要用来修饰变量、函数形参和类成员函数:
-
用 const 修饰常量:定义时就初始化,以后不能更改。
-
用 const 修饰形参:
func(const int a){};该形参在函数里不能改变 -
用 const 修饰类成员函数:该函数对成员变量只能进行只读操作,就是 const 类成员函数是不能修改成员变量的数值的。
被 const 修饰的东西都受到强制保护,可以预防意外的变动,能提高程序的健壮性。
const 在如下场景很容易混淆:
const int a; // a 是一个常整型数
int const a; // a 是一个常整型数
const int *a; // a 是一个指向常整型数的指针(也就是,整型数是不可修改的,但指针可以)
int * const a; // a 是一个指向整型数的常指针(也就是说,指针指向的整型数是可以修改的,但指针是不可修改的)
int const * a const; // a 是一个指向常整型数的常指针(也就是说,指针指向的整型数是不可修改的,同时指针也是不可修改的)
另外需要注意,const 修饰的局部变量在栈上分配空间,这个局部变量是可以修改的,而 const 修饰的全局变量在只读存储区分配空间。这个全局变量是不能修改的。
struct 内存对齐的 3 大规则
-
对于结构体的各个成员,第一个成员的偏移量是 0,排列在后面的成员其当前偏移量必须是当前成员类型的整数倍;
-
结构体内所有数据成员各自内存对齐后,结构体本身还要进行一次内存对齐,保证整个结构体占用内存大小是结构体内最大数据成员的最小整数倍;
-
如程序中有
#pragma pack(n)预编译指令,则所有成员对齐以 n 字节为准(即偏移量是 n 的整数倍),不再考虑当前类型以及最大结构体内类型。#pragma pack(1) struct fun{ int i; double d; char c; };sizeof(fun) = 13
struct CAT_s { int ld; char Color; unsigned short Age; char *Name; void(*Jump)(void); }Garfield;-
使用 32 位编译,int 占 4, char 占 1, unsigned short 占 2,char* 占 4,函数指针占 4 个,由于是 32 位编译是 4 字节对齐,所以该结构体占 16 个字节。(说明:按几字节对齐,是根据结构体的最长类型决定的,这里是 int 是最长的字节,所以按 4 字节对齐);
-
使用 64 位编译 ,int 占 4, char 占 1, unsigned short 占 2,char* 占 8,函数指针占 8 个,由于是 64 位编译是 8 字节对齐(说明:按几字节对齐,是根据结构体的最长类型决定的,这里是函数指针是最长的字节,所以按 8 字节对齐)所以该结构体占 24 个字节。
//64位 struct C { double t; //8 1111 1111 char b; //1 1 int a; //4 0001111 short c; //2 11000000 }; sizeof(C) = 24; //注意:1 4 2 不能拼在一起char 是 1,然后在 int 之前,地址偏移量得是 4 的倍数,所以 char 后面补三个字节,也就是 char 占了 4 个字节,然后 int 四个字节,最后是 short,只占两个字节,但是总的偏移量得是 double 的倍数,也就是 8 的倍数,所以 short 后面补六个字节。
-
联合体 union 内存对齐的 2 大规则
-
找到占用字节最多的成员;
-
union 的字节数必须是占用字节最多的成员的字节的倍数,而且需要能够容纳其他的成员
//x64 typedef union { long i; int k[5]; char c; }D要计算 union 的大小,首先要找到占用字节最多的成员,本例中是 long,占用 8 个字节,int k[5]中都是 int 类型,仍然是占用 4 个字节的,然后 union 的字节数必须是占用字节最多的成员的字节的倍数,而且需要能够容纳其他的成员,为了要容纳 k(20 个字节),就必须要保证是 8 的倍数的同时还要大于 20 个字节,所以是 24 个字节。
枚举 enum 内存对其
-
枚举的大小是按照 enum 中元素最大值所占的内存大小来决定的,不像结构体那样有多少个元素就按各个元素所占字节叠加;
- 当枚举成员的值小于 4 个字节时,占 4 个字节;
- 当枚举成员的值大于 4 个字节时,最大只能是 longlong 类型,占 8 个字节。
fwnode
The fwnode refers to a firmware node usually representing an entry in either Device Tree or ACPI (generally the DSDT table). Device Tree and ACPI are two different ways to define devices and their properties and interconnections between them. They both use tree structures to encode this information.
Simulators and Emulators
A simulator is designed to create an environment that contains all of the software variables and configurations that will exist in an app’s actual production environment. In contrast, an emulator attempts to mimic all of the hardware features of a production environment and software features.
简单来说,simulator 只需要模拟功能,至于这个功能的实现是不是和硬件实现一样,不重要;而 emulator 则需要实现和硬件运行流程一样的模拟。
Cache 一致性协议
在一个处理器系统上不同 CPU 内核中的高速缓存和内存可能具有同一数据的多个副本。维护高速缓存一致性的关键是跟踪每个 cache line 的状态,并根据处理器的读写操作和总线上相应的传输内容来更新高速缓存行在不同 CPU 内核上 cache 的状态。
cache 一致性协议主要有两大类:
- 总线监听协议:每个 cache 都要被监听或者监听其它 cache 的总线活动,主要是 MESI 协议;
- 目录协议:用于全局统一管理高速缓冲状态;
| 状态 | 描述 | 监听任务 |
|---|---|---|
| M 修改 (Modified) | 该 Cache line 有效,数据被修改了,和内存中的数据不一致,数据只存在于本 Cache 中。 | 缓存行必须时刻监听所有试图读该缓存行相对就主存的操作,这种操作必须在缓存将该缓存行写回主存并将状态变成 S(共享)状态之前被延迟执行。 |
| E 独享、互斥 (Exclusive) | 该 Cache line 有效,数据和内存中的数据一致,数据只存在于本 Cache 中。 | 缓存行也必须监听其它缓存读主存中该缓存行的操作,一旦有这种操作,该缓存行需要变成 S(共享)状态。 |
| S 共享 (Shared) | 该 Cache line 有效,数据和内存中的数据一致,数据存在于很多 Cache 中。 | 缓存行也必须监听其它缓存使该缓存行无效或者独享该缓存行的请求,并将该缓存行变成无效(Invalid)。 |
| I 无效 (Invalid) | 该 Cache line 无效。 | 无 |
内核启动时为什么要做线性映射
在 Linux 内核启动之后,对于 32 位的系统来说,他会把 0 ~ 896M 这部分低端内存(low memory)都做线性映射(映射到 ZONE_DMA 和 ZONE_NORMAL),不管这部分内存是否需要用到。对于 64 位的系统,内核会把所有的物理(一般情况如此,除非物理内存特别大)内存都映射出来(在内核地址空间中最高的 128 T 就用来做线性映射的)。这么做是为了访问效率,内核直接使用这些地址时,不需要重映射(即虚拟地址等于物理地址,不需要再经过页表的转换)。并且这些地址是大页映射,tlb miss 概率降低。一般来说,x86 和 arm64 都是 1G 或者 2M 的大页。采用大页映射的另一个好处是:页表的开销也会小很多。
进程间通讯
(1)有名管道/无名管道(2)信号(3)共享内存(4)消息队列(5)信号量(6)socket
线程通讯(锁)
(1)信号量(2)读写锁(3)条件变量(4)互斥锁(5)自旋锁
野指针与悬空指针
野指针(wild pointer)就是没有被初始化过的指针。
1 int main(int argc, char *argv[])
2 {
3 int *p;
4 return (*p & 0x7f); /* XXX: p is a wild pointer */
5 }
如果用 “gcc -Wall” 编译,会出现如下警告:
1 $ gcc -Wall -g -m32 -o foo foo.c
2 foo.c: In function ‘main’:
3 foo.c:4:10: warning: ‘p’ is used uninitialized in this function [-Wuninitialized]
4 return (*p & 0x7f); /* XXX: p is a wild pointer */
5 ^
悬空指针是指针最初指向的内存已经被释放了的一种指针。
1 #include <stdlib.h>
2 int main(int argc, char *argv[])
3 {
4 int *p1 = (int *)malloc(sizeof (int));
5 int *p2 = p1; /* p2 and p1 are pointing to the same memory */
6 free(p1); /* p1 is a dangling pointer, so is p2 */
7 p1 = NULL; /* p1 is not a dangling pointer any more */
8 return (*p2 & 0x7f); /* p2 is still a dangling pointer */
9 }
智能指针的本质是使用引用计数(reference counting)来延迟对指针的释放。
Spectre
Spectre: it is a subset of security vulnerabilities within the class of vulnerabilities known as microarchitectural timing side-channel attacks. 一个安全漏洞的 patch.
Zen 4
Zen 4: is the codename for a CPU microarchitecture by AMD, released on September 27, 2022. It is the successor to Zen 3 and uses TSMC’s 5 nm process. Zen 4 powers Ryzen 7000 mainstream desktop processors (codenamed “Raphael”) and will be used in high-end mobile processors (codenamed “Dragon Range”), thin & light mobile processors (codenamed “Phoenix”), as well as Epyc 7004 server processors (codenamed “Genoa” and “Bergamo”). CPU 微架构。
内存训练
好家伙,这么复杂,还是简单将其理解为内存初始化。其是 BIOS(不过现在是不是都用 ACPI 了)代码的一部分。
内核跟踪
-
现在我用的调试手段是 qemu + gdb 作为源码级调试;
-
硬件调试器,通过 jtag 直接连到硬件上,软件调试器,ldb/kgdb;
-
printk,根据 loglevel 输出信息,我也常用;
-
tracepoint,静态插桩,在一个插桩点上支持不同的插桩函数,这些插桩函数可以动态的注册或卸载。在执行到对应的 tracepoint 后,其会依次所有执行的函数;
-
ftrace,能够跟踪内核中的所有函数,以观察哪些函数对系统的性能产生较大的影响。如在一个时间段内,最长关抢占时间是多少,或线程从唤醒到实际执行的最长时间是多少等;
-
kprobe,上述的 tracepoint 和 ftrace 都是静态插桩,每次需要重新编译内核,效率低。kprobe 则支持对内核进行动态插桩,即在内核运行过程中动态地增加或减少插桩点,并在插桩点处执行对应的插桩函数。由于 kprobe 支持在几乎所有内核代码处进行插桩,因此当我们希望观测内核中某处代码的执行情况时,就可直接在该处增加一个插桩点,并为其实现对应的插桩函数。
当内核执行到该处代码之后,就会触发非法指令异常,此后内核将在异常处理流程中调用与该指令对应的 kprobe 插桩函数以及被保存的原始指令。若需要删除 kprobe 插桩点,则只需要将被保存代码还原回去即可。systemtap 和 ebpf 都是基于该技术实现的;
-
perf,前面都是通过跟踪点的方式实现内核观测功能的,它们的优点是能精确地跟踪到我们所期望的事件,但也可能对系统带来较大的性能损失。而且有时我们也希望能得到一些性能统计信息,以判断系统的一些运行状态。例如通过 cache miss 的统计数据,来观测当前的内存访问效率,或者通过分支预测数据,观测 cpu 流水线的情况等。perf 通过采样的方式来跟踪相关事件,其基本原理是对监测对象进行采样,然后在采样点中判断其相关上下文。即它是通过抽样统计方式,计算监测对象统计信息的。其中它的抽样事件由固定间隔的 cpu 中断触发,其通常为 tick 时钟中断;
binfmt_misc
binfmt_misc (Miscellaneous Binary Format) is a capability of the Linux kernel which allows arbitrary executable file formats to be recognized and passed to certain user space applications, such as emulators and virtual machines.
xxx@xxx /m/l/6/h/l/s/result> cd /proc/sys/fs/binfmt_misc/
xxx@xxx /p/s/f/binfmt_misc> ls
i386 jar python2.7 python3.7 register status x86_64
xxx@xxx /p/s/f/binfmt_misc> cat x86_64
enabled
interpreter /opt/LATX/latx-x86_64
flags:
offset 0
magic 7f454c4602010100000000000000000002003e00
mask fffffffffffefe00fffffffffffffffffeffffff
简而言之就是有了 binfmt_misc,如果可执行文件的 mask 和 magic 符合 binfmt_misc 下任一格式,那么就会调用对应的 interpreter 执行该可执行文件,从而达到执行异架构程序的效果。
Direct I/O
Direct I/O is a feature of the file system whereby file reads and writes go directly from the applications to the storage device, bypassing the operating system read and write caches. Direct I/O is used only by applications (such as databases) that manage their own caches. An application invokes direct I/O by opening a file with the O_DIRECT flag.
-
The primary benefit of direct I/O is to reduce CPU utilization for file reads and writes by eliminating the copy from the cache to the user buffer;
-
A second benefit of direct I/O is that it allows applications to avoid diluting the effectiveness of caching of other files.
Buffered I/O
Buffered I/O passes through the kernel’s page cache; it is relatively easy to use and can yield significant performance benefits for data that is accessed multiple times.
Coroutines
A coroutine is similar to a thread (in the sense of multithreading): it is a line of execution, with its own stack, its own local variables, and its own instruction pointer; but it shares global variables and mostly anything else with other coroutines. The main difference between threads and coroutines is that, conceptually (or literally, in a multiprocessor machine), a program with threads runs several threads in parallel. Coroutines, on the other hand, are collaborative: at any given time, a program with coroutines is running only one of its coroutines, and this running coroutine suspends its execution only when it explicitly requests to be suspended(next(it)).
手机 SOC 组成
-
AP=Application Processor=应用芯片=应用处理器=主 CPU=主控芯片=SoC:用来跑 app 的。往往集成其他硬件功能模块
- WiFi 芯片=802.11 b/g/n 相关芯片
- 蓝牙芯片=Bluetooth 4/5
- NFC 芯片
-
AF=Baseband Processor=基带芯片=射频套件:用来处理手机的(3G/4G/5G 的 GSM/CDMA/LTE/NR 不同网络制式)无线信号。包含:
- 射频=RF=Radio Frequency=无线电频率
- 射频发送和接收
- 频率合成
- 功率放大
- 基带=Baseband
- 信号处理
- 协议处理
- 射频=RF=Radio Frequency=无线电频率
Trustzone
The CoreLink TZC-400 TrustZone Address Space Controller (TZC-400) is an AMBA compliant System-on-Chip (SoC) peripheral(外围设备). It performs security checks on transactions to memory or peripherals. You can use the TZC-400 to create up to eight separate regions in the address space, each with an individual security level setting. Any transactions must meet the security requirements to gain access to the memory or peripheral. You can program the base address, top address, enable, and security parameters for each region.
kallsyms
在 2.6 版的内核中,为了更方便的调试内核代码,开发者考虑将内核代码中所有函数以及所有非栈变量的地址抽取出来,形成是一个简单的数据块(data blob:符号和地址对应),并将此链接进 vmlinux 中去。
00000000000197e0 A cpu_hw_events
000000000001ab18 A perf_nmi_tstamp
000000000001b000 A bts_ctx
000000000001e000 A insn_buffer
000000000001e008 A p4_running
000000000001e020 A pt_ctx
不同符号的含义可以使用 nm 命令查看:
nm - list symbols from object files
Page cache
Page cache 也叫页缓冲或文件缓冲,由几个磁盘块构成,大小通常为 4k,在 64 位系统上为 8k,构成的几个磁盘块在物理磁盘上不一定连续,文件的组织单位为一页, 也就是一个 page cache 大小,文件读取是由外存上不连续的几个磁盘块,到 buffer cache,然后组成 page cache,然后供给应用程序。
Page cache 在 linux 读写文件时,它用于缓存文件的逻辑内容,从而加快对磁盘上映像和数据的访问。具体说是加速对文件内容的访问,buffer cache 缓存文件的具体内容——物理磁盘上的磁盘块,这是加速对磁盘的访问。
Buffer cache
Buffer cache 也叫块缓冲,是对物理磁盘上的一个磁盘块进行的缓冲,其大小为通常为 1k,磁盘块也是磁盘的组织单位。设立 buffer cache 的目的是为在程序多次访问同一磁盘块时,减少访问时间。系统将磁盘块首先读入 buffer cache,如果 cache 空间不够时,会通过一定的策略将一些过时或多次未被访问的 buffer cache 清空。程序在下一次访问磁盘时首先查看是否在 buffer cache 找到所需块,命中可减少访问磁盘时间。不命中时需重新读入 buffer cache。对 buffer cache 的写分为两种,一是直接写,这是程序在写 buffer cache 后也写磁盘,要读时从 buffer cache 上读,二是后台写,程序在写完 buffer cache 后并不立即写磁盘,因为有可能程序在很短时间内又需要写文件,如果直接写,就需多次写磁盘了。这样效率很低,而是过一段时间后由后台写,减少了多次访磁盘的时间。
Buffer cache 是由物理内存分配,Linux 系统为提高内存使用率,会将空闲内存全分给 buffer cache ,当其他程序需要更多内存时,系统会减少 cache 大小。
Page cache 和 Buffer cache 的区别
磁盘的操作有逻辑级(文件系统)和物理级(磁盘块),这两种 Cache 就是分别缓存逻辑和物理级数据的。
假设我们通过文件系统操作文件,那么文件将被缓存到 Page Cache,如果需要刷新文件的时候,Page Cache 将交给 Buffer Cache 去完成,因为 Buffer Cache 就是缓存磁盘块的。
也就是说,直接去操作文件,那就是 Page Cache 区缓存,用 dd 等命令直接操作磁盘块,就是 Buffer Cache 缓存的东西。
Page cache 实际上是针对文件系统的,是文件的缓存,在文件层面上的数据会缓存到 page cache。文件的逻辑层需要映射到实际的物理磁盘,这种映射关系由文件系统来完成。当 page cache 的数据需要刷新时,page cache 中的数据交给 buffer cache,但是这种处理在 2.6 版本的内核之后就变的很简单了,没有真正意义上的 cache 操作。
简单说来,page cache 用来缓存文件数据,buffer cache 用来缓存磁盘数据。在有文件系统的情况下,对文件操作,那么数据会缓存到 page cache,如果直接采用 dd 等工具对磁盘进行读写,那么数据会缓存到 buffer cache。
mlockall
int mlockall(int flags);
flags 可取两个值:
- MCL_CURRENT: 表示对所有已经映射到进程地址空间的页上锁;
- MCL_FUTURE: 表示对所有将来映射到进程地空间的页都上锁。
函数将调用进程的全部虚拟地址空间加锁。防止出现内存交换,将该进程的地址空间交换到外存上。包括: 代码段,数据段,栈段,共享库,共享内存,user space kernel data, memory-mapped file。
此函数有两个重要的应用:
- real-time algorithms:对时间要非常高;
- high-security data processing: 如果数据被交换到外存上,可能会泄密。
通过 mlockall 锁定大量的内存对整个系统而言是危险的。不加选择的内存加锁可能会使系统死机,因为其余进程被迫争夺更少的资源,并且会更快地被交换进出物理内存(这被称之为 thrashing)。如果锁定了太多的内存,系统将整体缺乏必需的内存空间并开始杀死进程(OOM)。
而这种方式就叫做 pinning pages。
OOM reaper
经常出现 OOM Killer 不成功的情况,这通常是因为那些 “目标进程”因为等待锁而被阻塞,而在 OOM 状态下这些锁又无法被释放。如果一个被 OOM Killer 所选中杀死的进程得不到运行,它就无法退出,也就无法释放其内存;结果,导致整个 OOM Killer 机制失效。
OOM reaper 的核心思想是没有必要等待 “目标进程” 结束后再回收其大部分的内存。该进程已收到 SIGKILL 信号,这意味着它不会在用户模式下再次运行。也就是说,它也不会再访问其名下的任何匿名页(anonymous pages)。所以我们可以立即回收这些页框,这对最终的结果并不会造成什么影响。
OOM reaper 作为一个单独的线程实现;这样做是因为 reaper 必须能够不受干扰地在需要时立即开始运行并完成其工作。其他内核运行机制,例如工作队列(workqueues),在 OOM 状态下本身可能就会被阻塞,因此在此并不适用。内核加入该补丁后,在绝大多数 Linux 系统上 oom_reaper 线程大部分时间都处于空闲状态,只有当需要时才会被唤醒。
但是它仍然必须获取 mmap_sem 锁来释放页,这意味着如果 mmap_sem 被他人抢占,则该 reaper 线程也同样会被阻塞。
The Linux Staging tree
/drives/staging 目录包含一些还未充分测试或由于其他原因没有合入主线的驱动或文件系统。创建这个目录是为了用户能够更方便的访问这些驱动或文件系统,不用像之前那样从上百个网站下载文件了。
Bounce buffer
Bounce buffer 是指在 DMA 传输中,当设备要求直接访问内存时,但由于硬件或软件的限制,无法直接访问时所使用的缓冲区。这种情况下,内核会将原始的 DMA 传输请求拷贝到 bounce buffer 中,并将 bounce buffer 的地址提供给设备,设备会将数据写入 bounce buffer 中,然后由内核将数据从 bounce buffer 中复制到真正的内存地址中。这样就解决了设备无法直接访问内存的问题。
sg_table
在 Linux 内核中,sg_table 是用于管理散布/聚集(scatter/gather)I/O 的数据结构。散布/聚集 I/O 是一种技术,允许多个物理内存块(散布)或者多个数据片段(散布)组合成一个连续的内存区域,以便进行高效的数据传输。
sg_table 结构体定义在 <linux/scatterlist.h> 头文件中,它包含以下字段:
sgl:指向散布/聚集列表(scatter/gather list)的指针。散布/聚集列表是一组scatterlist结构体的数组,每个scatterlist结构体描述了一个散布/聚集 I/O 区域的相关信息。orig_nents:散布/聚集列表中的元素数量。nents:有效的散布/聚集列表元素数量。sgl_alloc_order:分配散布/聚集列表时使用的页数幂次。
通过使用 sg_table,驱动程序可以轻松地处理散布/聚集 I/O 的情况,而不需要直接操作散布/聚集列表。这简化了驱动程序的实现,并提供了更好的性能和灵活性。
SMMU
The MMU-600 contains the following key components:
-
Translation Buffer Unit (TBU)
The TBU contains Translation Lookaside Buffers (TLBs) that cache translation tables. The MMU-600 implements at least one TBU for each connected master, and these TBUs are local to the corresponding master.
-
Translation Control Unit (TCU)
The TCU controls and manages the address translations. The MMU-600 implements a single TCU. In MMU-600-based systems, the AMBA DTI protocol defines the standard for communicating with the TCU.
-
DTI interconnect
The DTI interconnect connects multiple TBUs to the TCU.
When an MMU-600 TBU receives a transaction on the TBS interface, it looks for a matching translation in its TLBs. If it has a matching translation, it uses it to translate the transaction and outputs the transaction on the TBM interface. If it does not have a matching translation, it requests a new translation from the TCU using the DTI interface.
When the TCU receives a DTI translation request, it uses the QTW interface to perform:
- Configuration table walks, which return configuration information for the translation context.
- Translation table walks, that return translation information that is specific to the transaction address.
The TCU contains caches that reduce the number of configuration and translation table walks that are to be performed. Sometimes no walks are required.
When the TBU receives the translation from the TCU, it stores it in its TLBs. If the translation was successful, the TBU uses it to translate the transaction, otherwise it terminates it.
ioremap
内核在访问外设或者 no-map 预留内存时只知道物理地址,需要使用 iormap 将物理地址映射为虚拟地址,对此,内核提供了一系列接口:
- ioremap & ioremap_nocache 实现相同,使用场景为映射 device memory 类型内存;
- ioremap_cached,使用场景为映射 normal memory 类型内存,且映射后的虚拟内存支持 cache;
- ioremap_wc & ioremap_wt 实现相同,使用场景为映射 normal memory 类型内训,且映射后的虚拟内存不支持 cache;
驱动开发
obj-m 表示把文件 test.o 作为”模块”进行编译,不会编译到内核,但是会生成一个独立的 “test.ko” 文件,调试它的话需要将其放到 initramfs 中,进入到内核后,执行 insmod test.o 进行挂载;
obj-y 表示把 test.o 文件编译进内核;
而如果需要添加一个驱动到内核中,需要按照如下步骤:
- 如果是新建文件夹,因为是分布式编译,需要在文件夹下添加一个 Makefile 文件和 Kconfig 文件并修改成指定格式,如果是单个文件直接添加,则直接修改当前目录下的 Makefile 和 Kconfig 文件将其添加进去即可;
- 如果是新建文件夹,需要修改上级目录的 Makefile 和 Kconfig,以将文件夹添加到整个源码编译树中;
- 执行 make menuconfig,查看对应的驱动是否加入到内核中,并置为 “Y” 或者 “M”,执行 make。
ioremap 和 memremap 应该用哪个
ioremap 返回的地址指针带 __iomem,__iomem 宏用于指定指针必须指向设备地址空间。如果指针指向其他空间,比如用户空间, 或者内核空间,那么 sparse checker 就会报 werror。__attribute((address_space(2))), 是用来修饰一个变量的,而且变量所在的地址空间必须是 2,即 I/O 空间。这里把程序空间分成了 3 个部分,0 表示 normal space,即普通地址空间,对内核代码来说, 就是内核空间地址;1 表示用户地址空间;2 表示是设备地址映射空间,例如硬件设备的寄存器在内核里所映射的地址空间。
内核中的 LRU 链表
新分配的页面不断地加入 ACTIVE LRU 链表中,同时 ACTIVE LRU 链表也不断地取出将页面放入 INACTIVE LRU 链表。链表中的锁(pgdat->lru_lock)竞争力度是非常强烈的,如果页面转移是一个一个进行的,那对锁的竞争将会十分严重。
为了改善这种情况,内核加入了一个 PER-CPU 的 LRU 缓存(用 struct pagevec 表示),页面要加入 LRU 链表会先放入当前 CPU 的 LRU 缓存 中,直到 LRU 缓已经满了(一般为 15 个页面),再获取 lru_lock,一次性将这些页面批量放入 LRU 链表(这个思路很简单,直观来看,应该很有效)。
PCP(per cpu page)
由于内存页面属于公共资源,系统中频繁分配释放页面,会因为获得释放锁(zone->lock),CPU 之间的同步操作产生大量消耗。同样为了改善这种情况,内核加入了缓存(struct per_cpu_pages 表示),每个 CPU 都从 Buddy 批发申请少量的页面存放在本地。当系统需要申请内存时,优先从 PCP 缓存拿,用完了再从 buddy 批发。释放时也优先放回该 PCP 缓存,缓存满了再放回 buddy 系统(之前一直不理解为啥在 buddy 分配单个 page 时,会先从 pcp 里面申请,原来如此)。
DMA
之前对 dma 的理解仅限于它是直接在内存和外设之间搬数据的设备之类的东西,但是对于其在内核中是怎样工作的一直不理解。
DMA(Direct Memory Access) 像普通的外设一样提供一组控制/状态、数据、中断 Linux 内核里把 DMA 分为 provider 和 client 两种角色。
所谓 provider 就是 DMA 控制器驱动,它直接访问寄存器,提供 DMA 通道,但并不提供用户态可用的系统调用或设备文件,而 client 则申请使用 DMA 通道,结合具体外设实现真正的驱动功能。
很多时候 DMA 并不是独立工作的,而是要和其他与内存之间有数据搬运的外设结合到一起,例如 ADC 使用 DMA 将采集到的电压值写入给定内存,SPI 使用 DMA 不断将内存中的数据搬运到 SPI 数据寄存器从而实现发送。
Linux 内核实现了 dmaengine,封装了 DMA client 驱动开发的统一接口,提出了实现 DMA 控制器驱动的接口要求,三者之间的关系可以看下面这张图:

在 DMA Client 驱动中粗略的讲要做下面的事情:
- 使用 dma_request_channel 申请使用 DMA 通道;
- 为 DMA 操作申请一致性内存;
- 构造 struct dma_async_tx_descriptor;
- 使用 dmaengine_submit 启动传输;
- 使用 dma_async_is_tx_complete 检查传输状态;
- dmaengine_terminate_all 终止传输;
genalloc
内核中有许多内存分配子系统,每一个都是针对特定的需求。然而,有时候内核开发者需要为特定范围的特殊用途的内存实现一个新的分配器;通常这个内存位于某个设备上。该设备的驱动程序的作者当然可以写一个小的分配器来完成工作,但这是让内核充满几十个测试 差劲的分配器的方法。早在 2005 年,Jes Sorensen 从 sym53c8xx_2 驱动中提取了其中的一 个分配器,并将其作为一个通用模块发布,用于创建特设的内存分配器。
gen_pool_create用来创建一个内存池,主要是创建struct gen_pool结构体。分配的粒度由min_alloc_order设置;它 是一个以 2 为底的对数,表示多少字节对齐。因此,如果min_alloc_order被传递为3,那么所有的分配将是 8 字节的倍数。gen_pool_add用来将从地址(在内核的虚拟地址空间)开始的内存的大小字节放入给定的池中,再次使用 nid 作为节点 ID 进行辅助内存分配。gen_pool_add_virt变体将显式物理地址与内存联系起来;只有在内存池被用于 DMA 分配时,这才是必要的。gen_pool 的内存不是从 buddy 中申请的,而是设备自己的内存,采用 genpool 算法管理;-
gen_pool_alloc将从给定的池中分配 size 个字节。gen_pool_dma_alloc变量分配内存用于 DMA 操作,返回 dma 所指向的空间中的相关物理地址。这只有在内存是用gen_pool_add_virt添加的情况下才会起作用; gen_pool_alloc_algo进行的分配指定了一种用于选择要分配的内存的算法。
nGnRnE
内核代码中关于页面属性有这样一个配置:nGnRnE,它们有如下含义:
-
Gathering 或者non Gathering (G or nG)。这个特性表示对多个memory的访问是否可以合并,如果是nG,表示处理器必须严格按照代码中内存访问来进行,不能把两次访问合并成一次。例如:代码中有2次对同样的一个地址的读访问,那么处理器必须严格进行两次read transaction;
-
Re-ordering (R or nR)。这个特性用来表示是否允许处理器对内存访问指令进行重排。nR表示必须严格执行program order;
-
Early Write Acknowledgement (E or nE)。PE访问memory是有问有答的(更专业的术语叫做transaction),对于write而言,PE需要write ack操作以便确定完成一个write transaction。为了加快写的速度,系统的中间环节可能会设定一些write buffer。nE表示写操作的ack必须来自最终的目的地而不是中间的write buffer;
Per-CPU
将一个共享 memory 变成 Per-CPU memory 本质上是一个耗费更多 memory 来解决 performance 的方法。当一个在多个 CPU 之间共享的变量变成每个 CPU 都有属于自己的一个私有的变量的时候,我们就不必考虑来自多个 CPU 上的并发,仅仅考虑本 CPU 上的并发就 OK 了。当然,还有一点要注意,那就是在访问Per-CPU 变量的时候,不能调度,当然更准确的说法是该 task 不能调度到其他 CPU 上去(调度到其他 CPU 就访问不到对应的 Per-CPU 变量了)。目前的内核的做法是在访问 Per-CPU 变量的时候 disable preemptive,虽然没有能够完全避免使用锁的机制(disable preemptive 也是一种锁的机制),但毫无疑问,这是一种代价比较小的锁。
Android 内存指标
-
VSS: virtual set size 虚拟耗用内存;
-
RSS: resident set size 进程+共享库耗用的物理内存总和;
-
PSS: proportional set size 进程+部分共享库(n 个进程使用该共享库,其中一个进程就占 1/n)占用的物理内存总和;
-
USS: unique set size 进程独自占用的物理内存;
可以通过 adb shell procrank 命令来查看系统当前运行中各个进程各部分内存消耗。一般将 PSS 作为实际使用内存的指标来进行监控,其能比较准确的表示进程占用的实际物理内存。
might_sleep
might_sleep 是内核中一个非常重要的宏定义,用于标记一个代码路径是否可能导致睡眠。如果当前运行的上下文已经是不允许睡眠的,那么这个代码路径将会引发内核的一个 panic,从而防止系统出现死锁或其他严重问题。
static inline
在头文件中使用 inline 时务必加入 static,否则当 inline 不内联时就和普通函数在头文件中的定义一样,当多个 .c 引用时会出现重定义(使用 #ifdef 能避免这种情况么)。inline 可能不内联是因为 inline 关键字是建议内联不是强制内联,gcc 中 O0 优化时不内联。
那为什么要在头文件中定义函数呢?有些简单的函数,不希望增加一次函数调用的时间,那么可以通过宏来解决,但是接口使用宏不够清晰,那么选择 inline,然后就变成了 static inline。
缺页中断
DEFINE_IDTENTRY_RAW_ERRORCODE(exc_page_fault)
unsigned long address = read_cr2();在 X86 架构中,cr2 寄存器保存着访存时引发 #PF 异常的线性地址,cr3 寄存器提供页表的基地址(在mm_struct中也保存有页表基地址,cr3 寄存器中的值应该是在进程切换时从mm_struct中写入进去的);handle_page_faultdo_kern_addr_fault内核地址空间引发的中断;do_user_addr_fault用户地址空间引发的中断;
dup 系统调用
dup 函数是用来打开一个新的文件描述符,指向和 oldfd 同一个文件,共享文件偏移量和文件状态。
dup2 函数,把指定的 newfd 也指向 oldfd 指向的文件,也就是说,执行完 dup 2之后,有 newfd 和 oldfd 同时指向同一个文件,共享文件偏移量和文件状态。
dma_mask
dma_mask 表示的是该设备通过 DMA 方式可寻址的物理地址范围(其实从内核注释来看,这个就是表示该设备是否支持 dma),如果没有配置,说明该设备不具备 DMA 寻址能力,在使用 dma_map_sgtable 类接口映射时会报错;
coherent_dma_mask 表示所有设备通过 DMA 方式可寻址的公共的物理地址范围(从功能上该变量和 dma_mask 有所重叠,但这个变量是用在 alloc_coherent 类接口上的),其往往会和 dev->bus_dma_limit 结合,得到 dma 寻址的上下限。如果没有配置,那么使用 dma_alloc_coherent 等接口申请内存时,会报错。dma_coherent_ok 函数能够判断访问的物理地址是否超过了该设备支持的 dma 内存范围;
在使用时不用区分的如此细致,使用 dma_set_mask_and_coherent 接口都会进行配置,但是要注意 dma 的寻址范围。
与这两者类似的还有 dev->dma_coherent,表示该设备是否自己支持 dma 内存一致性,该变量能够通过 dts 配置,在 设备初始化流程的arch_setup_dma_ops 函数进行赋值,如果支持,那后续刷 cache 的接口就不会执行。
why soc?
讲 SoC 前我们先看下传统的 PC 构架,当你去买电脑的时候,首先决定价位的就是 CPU,然后就是显卡、声卡、无线网卡等各种配件,最后电脑攒出来了,一个机箱个头不小啊,耗电也是响当当的。家里插电还可以用,但是对于手机、汽车等移动设备来说,电池供电再这么搞是不行了,系统对省电、体积、功能有更高的要求,需要越来越多的模块,解决方案就是SoC。
随着芯片的集成化程度提升,很多模块都做到芯片的内部,比如 isp、dsp、gpu,这样做成片上系统(System on Chip,简称 SoC),好处是整个系统功能更内聚,板级面积会减少,但是芯片的体积却越来越大。大的芯片面积造成芯片成本和功耗增加,但是整体功耗相对减小,随着芯片制造工艺的提高,可以提高能耗比和降低成本。
PageFlags
PG_locked:该页已被上锁,通常表明有进程在进行硬盘 I/O 操作。;PG_writeback:该页正在被写到磁盘上;PG_referenced:该页刚刚被访问过,该标志位与 PG_reclaim 标志位共同被用于匿名与文件备份缓存的页面回收;PG_uptodate:该页处在最新状态(up-to-date),当对该页完成一次读取时,该页便变更为 up-to-date 状态,除非发生了磁盘 IO 错误;PG_dirty:该页为脏页,即该页的内容已被修改,应当尽快将内容写回磁盘上;PG_lru:该页处在一个 LRU 链表上;PG_head:在内核中有时需要将多个页组成一个 compound pages,而设置该状态时表明该页是 compound pages 的第一个页;PG_waiters:有进程在等待该页面;PG_active:该页面位于活跃 lru 链表中;PG_workingset:该页位于某个进程的 working set(工作集,即一个进程同时使用的内存数量,例如一个进程可能分配了114514MB内存,但是在同一时刻只使用其中的1919MB,这就是工作集)中;PG_error:该页在 I/O 过程中出现了差错;PG_slab:该页由 slab 使用;PG_owner_priv_1:该页由其所有者使用,若是作为 pagecache 页面,则可能是被文件系统使用;PG_arch_1:该标志位与体系结构相关联;PG_reserved:该页被保留,不能够被 swap out(内核会将不活跃的页交换到磁盘上);PG_private&&PG_private2:该页拥有私有数据(private 字段);PG_mappedtodisk:该页被映射到硬盘中;PG_reclaim:如果页面是 dirty 或者处于 writeback 状态,那么这种页面会放到不活跃链表头,并设置该标记位,表示该页可以被回收;PG_swapbacked:swapcache 表示匿名页面已经交换(swap)到磁盘中,而 SwapBacked,表示匿名页面的内容已经从磁盘换回(backed)到内存中;PG_unevictable:该页不可被回收(被锁),且会出现在LRU_UNEVICTABLE链表中;PG_mlocked:该页被对应的 vma 上锁(通常是系统调用 mlock);PG_uncached:该页被设置为不可缓存;PG_hwpoison:硬件相关的标志位;PG_young:PG_idle:PG_arch_2:64位下的体系结构相关标志位;
内核不会直接使用这些 flags,而是通过 folio_set_xxx 来使用,如 folio_set_locked,folio_test_locked,folio_clear_locked。
kmap/vmap/ioremap
-
vmap 用于相对长时间的映射,可同时映射多个 pages,需要 page 结构作为入参;
- kmap 和 kmap_atomic 则用于相对短时间的映射,只能映射单个 page;
- ioremap 函数,其功能是将给定的物理地址映射为虚拟地址;
ATF
ARM 可信任固件(ARM Trustedd Firmware, ATF)是由 ARM 提供的底层固件,该固件统一了 ARM 底层接口标准,如电源状态控制接口(Power Status Control Interface, PCSI), 安全启动需求(Trusted Board Boot Requirements, TBBR),安全世界状态(SWS)和正常世界状态(NWS)切换的安全监控模式调用(secure monitor call, smc)操作等。ATF 旨在将 ARM 底层的操作统一使代码能够重用和便于移植。其提供了安全世界的参考实现软件,https://github.com/ARM-software/arm-trusted-firmware.
AVF
android virtualization framework,在 KVM 的基础上开发,不过它的安全性比 KVM 要更高,其实现了一个 pKVM(protected Kernel-based Vitral Machine),运行在 EL2,kernel 运行在 EL1,加载过程如下图所示,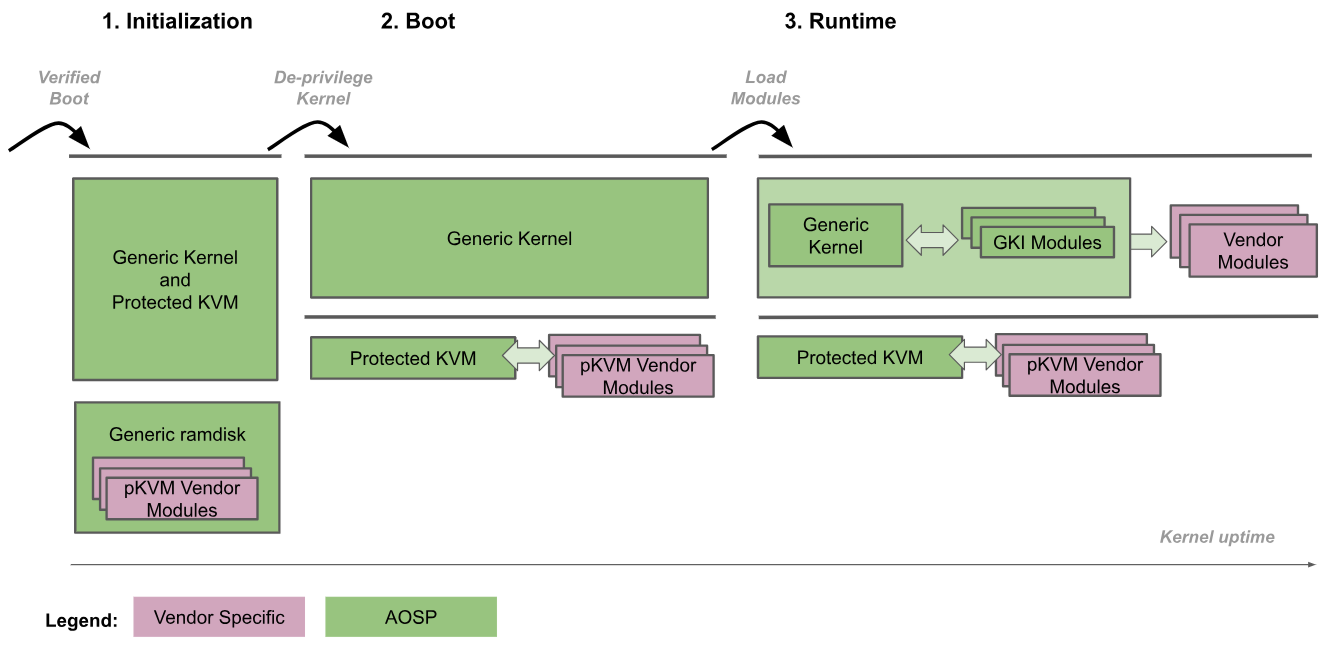
-
引导加载程序以 EL2 进入通用内核;
-
通用内核检测到它在以 EL2 运行,并将自身权限下调至 EL1,而 pKVM 及其模块会继续以 EL2 运行。此外,此时还会加载 pKVM 供应商模块;
-
通用内核会继续正常启动,加载所有必要的设备驱动程序,直至到达用户空间为止。此时,pKVM 已就位并处理第 2 阶段页面表格。
启动过程会信任引导加载程序,以便仅在前期启动期间保持内核映像的完整性。在内核调低权限后,Hypervisor 将不再认为内核可信,并将负责进行自我保护,即使内核遭到入侵也不例外。也就是说,host kernel 被攻击也不会影响其他的虚拟机。
memset
memset 的作用是传入一个虚拟地址,将虚拟地址对应的内存中的数据清理掉,写成指定的数据。但是这样会有一个问题,如果要清理的内存太大,会导致 cache 浪费,将 cache 全部占满,但又是无效数据。为了解决这一问题,ARM 给出了一个解决方案,write streaming mode,也就是在识别到 ACPU 写入一系列完整的 cacheline 时,就会进入 write streaming mode,根据写入的数据大小,将数据直接写入到 L2, L3, DDR 中,这样就可以避免污染 cache。
但从软件架构上来说,如果有非 ACPU 侧的 master 访问该块内存,还是要在访问之前进行 clean cache 操作,确保数据全部写入到 DDR 中,因为 write streaming mode 很难保证每个字节都是直接写入到 L2, L3, DDR 中。
SVC/HVC/SMC
- The Supervisor Call (SVC) instruction enables a user program at EL0 to request an OS service at EL1;
- The Hypervisor Call (HVC) instruction, available if the Virtualization Extensions are implemented, enables the OS to request hypervisor services at EL2;
- The Secure Monitor Call (SMC) instruction, available if the Security Extensions are implemented, enables the Normal world to request Secure world services from firmware at EL3;
When the PE is executing at EL0, it cannot call directly to a hypervisor at EL2 or secure monitor at EL3, as this is only possible from EL1 and higher. The application at EL0 must use an SVC call to the kernel, and have the kernel perform the action to call into higher Exception levels.

get_user_pages
该函数通过查询页表找到的 pte 对应的 page 结构体,但是若是页表或者物理页尚未创建成功,那么 __get_user_pages 会通过 faultin_page 模拟一个缺页中断,完成相关物理页及页表建立,然后再执行 pin 的动作。
SVE
随着 Neon 架构扩展(其指令集具有固定的 128 位向量长度)的开发,Arm 设计了可扩展向量扩展 (SVE) 作为 AArch64 的下一代 SIMD 扩展。SVE 引入可扩展概念, 允许灵活的向量长度实现,使其能够在现在或将来的多应用场景下实现伸缩,允许 CPU 设计者自由选择向量的长度来实现。矢量长度可以从最小 128 位到最大 2048 位不等,以 128 位为增量。SVE 的设计保证同样的应用程序可以在支持 SVE 的不同实现上执行,而无需重新编译代码。 SVE 提高了架构对高性能计算 (HPC) 和机器学习 (ML) 应用程序的适用性,这些应用程序需要大量数据处理。
spectre 漏洞
由于 cpu 具有多级流水线和分支预测功能,在分支预测时可能会将该分支对应的数据提前加载到 cache 中。一旦分支预测失败,则由于另一分支的数据未被加载到 cache,因此其访问速度和预测成功时相比会慢的多。因此攻击者可能利用这种执行速度的差异来判断分支预测是否成功,而失败分支的数据依然还位于 cache 中。因此,攻击者最终可能有机会从 cache 中获取该数据,从而造成数据泄露。这就是 spectre 漏洞,其本质是利用侧信道方式攻击 cache 中的数据。vector slots 中不同 slot 中的 vector 就是根据硬件能力,用于防止不同等级 spectre 漏洞的向量表集合。
break-before-make
我们在使用 ARM MMU 一般会遵循如下流程:
- 配置 TTBR、TCR 和 MAIR 等 MMU 配置寄存器;
- 配置页表 pagetable,VA 和 PA 的映射关系,地址空间属性等等;
- 使能MMU和cache;
即先配置好 pagetable 再使能 MMU 和 cache,在 MMU 和 cache 使能之后,如果想要在程序运行时,动态改变 pagetable 或者称为 translation table,需要遵循一定的规则(break-before-make)才能保证其安全性和可靠性。它有如下步骤:
- 先将页表中老旧的页表条目(old translation table entry)用无效的条目来替代,也就是先将该转换关系给禁止;
- 执行一个 DSB 内存屏障指令,以确保该替换操作生效;
- 针对该页表条目执行一个广播的 TLB invalidate 指令,将 TLB 中缓存的旧页表条目信息删除;
- 执行一个 DSB 内存屏障指令,以确保 TLB invalidate 指令操作生效;
- 然后将新的页表条目写入;
- 执行一个 DSB 内存屏障指令,以确保新的页表条目更新成功;
simulator/emulator
模拟器(simulator)是用于分析研究目标系统本身,模拟器系统本身要跟目标系统保持一致。例如飞行模拟器对于用户来讲其本身要跟真正的飞机一致;再比如gem5模拟器,其本身要跟CPU所有内部行为一致(包括内部运行原理都要一致)。好的模拟器本身也可以仿真其目标系统,但不是所有模拟器都有这个特性。
仿真器(emulator)的目的是作为目标系统的替代品,可以完全替代目标系统,完成其对外的功能,即仿真器系统只需要保证呈现给外部的行为跟目标系统一致(不需要保证内部运行原理一致)。使用仿真器的目的是模拟目标系统呈现出的运行环境,仿真器保证的是完成目标系统相同的行为,不在乎其内部实现原理,再例如EMU8086仿真器,可以在另一台非8086电脑上仿真8086微处理器的行为。即使再好的仿真器也不能作为模拟器用于研究目标系统内部运行原理。
芯片设计
芯片设计流程通常可分为:数字 IC 设计流程和模拟 IC 设计流程。
数字 IC 设计流程:芯片定义 → 逻辑设计 → 逻辑综合 → 物理设计 → 物理验证 → 版图交付。
芯片定义(Specification)是指根据需求制定芯片的功能和性能指标,完成设计规格文档,HLD;
逻辑设计(Logic Design)是指基于硬件描述语言在 RTL(Register-Transfer Level)级(买的 IP 就是这个)实现逻辑设计,并通过逻辑验证或者形式验证等验证功能正确;
逻辑综合(Logic Synthesis)是指将 RTL 转换成特定目标的门级网表(这个就是用 EDA 转化的),并优化网表延时、面积和功耗;
物理设计(Physical Design)是指将门级网表根据约束布局、布线并最终生成版图的过程,其中又包含:数据导入 → 布局规划 → 单元布局 → 时钟树综合 → 布线。
-
数据导入是指导入综合后的网表和时序约束的脚本文件,以及代工厂提供的库文件;
-
布局规划是指在芯片上规划输入/输出单元,宏单元及其他主要模块位置的过程;
-
单元布局是根据网表和时序约束自动放置标准单元的过程;
-
时钟树综合是指插入时钟缓冲器,生成时钟网络,最小化时钟延迟和偏差的过程;
-
布线是指在满足布线层数限制,线宽、线间距等约束条件下,根据电路关系自动连接各个单元的过程;
物理验证(Physical Verificaiton)通常包括版图设计规则检查(DRC),版图原理图一致性检查(LVS)和电气规则检查(ERC)等;
版图交付(Tape Out)是在所有检查和验证都正确无误的前提下,传递版图文件给代工厂生成掩膜图形,并生产芯片;
模拟 IC 设计流程:芯片定义 → 电路设计 → 版图设计 → 版图验证 → 版图交付。
其中芯片定义和版图交付和数字电路相同,模拟IC在电路设计、版图设计、版图验证和数字电路有所不同。
模拟电路设计是指根据系统需求,设计晶体管级的模拟电路结构,并采用SPICE等仿真工具验证电路的功能和性能。
模拟版图设计是按照设计规则,绘制电路图对应的版图几何图形,并仿真版图的功能和性能。
模拟版图验证是验证版图的工艺规则、电气规则以及版图电路图一致性检查等。
这里,做一个简单的总结:
芯片设计:就是在EDA工具的支持下,通过购买 IP 授权自主研发(合作开发)的 IP,并遵循严格的集成电路设计仿真验证流程,完成芯片设计的整个过程。在这个过程中,EDA、IP、严格的设计流程三者缺一不可。
GUP
相比用户空间的缺页机制,Get User Pages(GUP) 机制则提供了另外一种思路,其允许内核线程访问未映射物理内存的用户空间虚拟内存,然后通过提前缺页(PreFault)的方式分配物理内存,并建立页表将用户虚拟内存映射到物理内存上,那么用户进程可以直接访问虚拟内存而不会触发缺页,除此之外, GUP 机制还支持以下功能:
- PreFault:内核线程可以让未映射物理内存的用户空间虚拟内存提前发生缺页(PreFault),然后内核线程获得对应的物理内存,并采用临时映射向物理页写入指定数据,那么用户进程可以从虚拟内存里读到预设的数据;
- PreAlloc:用户进程采用 SYS_MMAP 系统调用分配虚拟内存时,可以借助 GUP 机制在分配虚拟内存的同时也分配物理内存,并建立好页表映射,这样用户进程可以直接使用分配好的虚拟内存;
- 锁定页面:在进行某些操作时(如进行直接内存访问 DMA 操作),需要页面保持不动,不被交换出去。GUP 提供的页面锁定确保在操作进行期间,页面保留在物理内存中;
- 检测进程虚拟内存:内核线程可以通过 GUP 机制访问指定用户进程的虚拟内存对应的物理页,那么内核线程可以使用物理页内容,以此影响或检测应用程序的行为;
FOLL_WRITE: 检查页面表条目是否可写, 通常用于确保页面的写操作不会因写保护而失败
FOLL_TOUCH: 标记页面为已访问, 这可以更新页面的访问时间,用于页面老化和替换算法
FOLL_DUMP: 通常用于进程的核心转储和错误报告,处理内存区域中的空洞
FOLL_TRIED: 表示操作重试,意味着之前的尝试已经开始了 I/O
FOLL_REMOTE: 表示在非当前任务 /mm 上操作,通常用于远程任务内存操作
FOLL_ANON: 在操作期间更倾向于使用匿名内存(即,不由文件支持的内存)
FOLL_HWPOISON: 检查页面是否已被硬件标记为坏(由于错误)
FOLL_MIGRATION: 等待页面替换其迁移条目。这在内核的内存迁移上下文中使用
FOLL_FORCE: 允许无视当前权限读写页面。这是一个强大的选项,应谨慎使用,因为它绕过了标准内存保护机制
FOLL_NOWAIT: 如果需要(例如,对于换入页面的交换),启动所需的磁盘I/O,但不等待I/O完成。这可以在某些场景中提高响应性
FOLL_NOFAULT: 在访问页面时不引起页面错误。这在某些页面错误代价高昂或不希望发生错误的场景中有用
FOLL_NUMA: 强制 NUMA(非统一内存访问)提示,可以影响多节点系统上的页面放置决策,优化内存访问模式
FOLL_GET: 通过 get_page 增加页面的引用计数, 这对确保页面在使用时保留在内存中至关重要
FOLL_LONGTERM: 表明映射的生命周期是无限的,这可能会影响内核如何处理这些页面,比如关于交换或回收
FOLL_SPLIT_PMD: 在返回之前拆分巨大的页面表映射(PMDs), 这与处理巨大页面或透明巨大页面有关
FOLL_PIN: 表明页面必须通过 unpin_user_page() 来释放,通常与页面固定函数一起使用,确保它们在显式取消固定之前保持在内存中
FOLL_FAST_ONLY: 与快速用户页面查找功能一起使用,防止在快速路径失败时回退到更慢的方法
ptrace 系统调用
该系统调用是用于进程跟踪的,它提供了父进程可以观察和控制其子进程执行的能力,并允许父进程检查和替换子进程的内核镜像(包括寄存器)的值。其基本原理是:当使用了 ptrace 跟踪后,所有发送给被跟踪的子进程的信号(除了 SIGKILL),都会被转发给父进程,而子进程则会被阻塞,这时子进程的状态就会被系统标注为 TASK_TRACED。而父进程收到信号后,就可以对停止下来的子进程进行检查和修改,然后让子进程继续运行。ptrace 是如此的强大,以至于有很多大家所常用的工具都基于 ptrace 来实现,如 strace 和 gdb。
ftrace
ftrace 是众多 trace 工具中的一种,

CPU 投机访问
所谓投机访问跟 prefetch 类似的,CPU 根据之前执行的 pattern 预测下一次可能会访问的地址,向 MMU 发起访问,由 MMU 读取页表找到对应的 pte,如果该块内存是 device memroy(stage1/stage2 任意一个),那么 MMU 就不会返回物理地址,预取失败,否则返回物理地址,CPU 会去读取该块内存放到 cache 中。CPU 执行时感知不到内核在执行什么进程,它就是根据自己定义好的预取规则执行操作。
另外还有个问题,在使能了虚拟化的机器上,投机访问是怎样进行的?会去 hypervisor 使用的页表中投机么?会的。
什么时候 CPU 不会进行投机访问?
虚拟总线
相对于 USB、PCI、I2C、SPI 等物理总线来说,platform 总线是一种虚拟、抽象出来的总线,实际中并不存在这样的总线。
那为什么需要 platform 总线呢?
因为对于 usb 设备、i2c 设备、pci 设备、spi 设备等等,他们与 cpu 的通信都是直接挂在相应的总线下面与我们的 cpu 进行数据交互的,但是在嵌入式系统中,并不是所有的设备都能够归属于这些常见的总线。在嵌入式系统里面,SoC 系统中集成的独立的外设控制器、挂接在 SoC 内存空间的外设(IOMMU/SMMU 等)却不依附与此类总线。所以 Linux 驱动模型为了保持完整性,将这些设备挂在一条虚拟的总线上(platform总线),而不至于使得有些设备挂在总线上,另一些设备没有挂在总线上。
pkill -9 之后发生了什么
程序实际上从未接收到 SIGKILL 信号,因为 SIGKILL 完全由操作系统/内核处理。
当发送特定进程的 SIGKILL 时,内核的调度程序立即停止给该进程更多运行用户空间代码的 CPU 时间。如果在调度程序做出此决定时,进程在其他 CPU /核心上有执行用户空间代码的线程,那么这些线程也将被停止。(在单核系统中,这过去要简单得多:如果系统中唯一的 CPU 核心运行调度程序,那么根据定义,它就不是同时运行进程了!)
如果进程/线程在执行 SIGKILL 时正在执行内核代码(例如系统调用,或与内存映射文件相关联的 I/O 操作),则会变得更加棘手:只有一些系统调用是可中断的,因此内核在内部将进程标记为处于特殊的“死亡”状态,直到系统调用或 I/O 操作被解析为止。解决这些问题的 CPU 时间将和往常一样安排。可中断系统调用或 I/O 操作将检查调用它们的进程是否处于任何适当的停止点,并且在这种情况下会提前退出。不间断操作将运行到完成,并在返回到用户空间代码之前检查是否处于“死亡”状态。
一旦解析了进程内的内核例程,进程状态就从“运行”变为“死亡”,内核开始清理它,就像程序正常退出时一样。清理完成后,将分配大于 -128 的结果代码(以指示进程被信号杀死;关于混乱的细节,请看这个答案),进程将转换为“僵尸”状态。将使用 SIGCHLD 信号通知终止进程的父进程。
所以,进程本身永远不会有机会实际处理它已经接收到 SIGKILL 的信息。
WFE/WFI
这两条指令都是让 CPU 进入 low-power standby state,即保持供电,关闭 clock。
不同点在于,对 WFI 来说,执行 WFI 指令后,ARM core 会立即进入 low-power standby state,直到有 WFI Wakeup events 发生。
而 WFE 则稍微不同,执行 WFE 指令后,根据 Event Register(一个单 bit 的寄存器,每个 PE 一个)的状态,有两种情况:如果 Event Register 为 1,该指令会把它清零,然后执行完成(不会 standby);如果 Event Register 为 0,和 WFI 类似,进入 low-power standby state,直到有 WFE Wakeup events 发生。
near/far-atomics
Atomic operations performed internally by a fully coherent Request Node (RN-F) are called near-atomics. Atomic operations that are performed externally to the Requester are called far-atomics.
TTBR
TTBR 是 Translation Table Base Register 的意思,即 ARM 中的基址寄存器。
-
TTBR0_EL1/TTBR1_EL1:EL1 OS 使用的用户态转换页表基地址和内核态转换页表基地址;
-
TTBR0_EL2/TTBR1_EL2:EL2 Hypervisor 使用的转换页表基地址;
-
TTBR0_EL3:EL3 仅有 Stage 1 转换页表基地址;
-
VTTBR_EL2:虚拟化场景下页表转换 Stage 2 基地址。
THIS_MODULE
ARM NEON 指令
软核、硬核和固核
CMN-600
CMN600ae是基于Mesh拓扑结构,对外支持AMBA CHI/ACE-LITE等接口,内部改用路由结构转发数据,并提供硬件一致性和系统缓存,还支持多芯片互联。CMN600在T16FFC上可以做到2Ghz,另外AE版本增加了车轨芯片的安全功能,总线内部采用EDC检查,接口采用的奇校验。
事件相机
事件相机可以简单理解为一种“仅感知运动物体”的传感器。在事件相机的每个像素处都有一个独立的光电传感模块,当该像素处的亮度变化超过设定阈值时,就会生成、输出事件数据(有时也称脉冲数据)。另外,由于所有的像素都是独立工作的,所以事件相机的数据输出是异步的,在空间上呈现稀疏的特点。这也是事件相机与标准相机的最大不同之处,也是事件相机的核心创新。这种成像范式的好处是可以大大减少冗余数据,从而提高后处理算法的计算效率。
域控制器
域控制器是汽车每一个功能域的核心,它主要由域主控处理器、操作系统和应用软件及算法等三部分组成。平台化、高集成度、高性能和良好的兼容性是域控制器的主要核心设计思想。依托高性能的域主控处理器、丰富的硬件接口资源以及强大的软件功能特性,域控制器能将原本需要很多颗 ECU 实现的核心功能集成到一起来,极大提高系统功能集成度,再加上数据交互的标准化接口,因此能极大降低这部分的开发和制造成本。
对于功能域的具体划分,各汽车主机厂家会根据自身的设计理念差异而划分成几个不同的域。比如 BOSCH 划分为5个域:动力域(Power Train)、底盘域(Chassis)、车身域(Body)、座舱域(Cockpit/Infotainment)、自动驾驶域(ADAS)。
当前汽车 E/E 架构的发展进程是:分布式 -> 域集中控制 -> 中央集中
kprobe
Kprobe 的基本原理可以概括为:
将原来的指令记录在 struct *kprobe 的 opcode 变量中,将原来的指令替换成 brk 指令。CPU 执行到 brk 指令时,就会执行到 kprobe 的异常回调函数。在异常回调函数中根据发生异常的地址来找到对应的 kprobe(kprobe 的 addr 域记录着地址),执行 kprobe 的pre_handler 函数。
更概括的说法是:将本来执行一条指令扩展成执行 kprobe->pre_handler—>指令—> kprobe–>post_handler。pre_handler 和 post_handler 都是自定义在 struct *kprobe 结构体中的回调函数。
Kprobe 的使用需要通过 register_kprobe 来注册 kprobe 点,详细原理可以参考这篇文档。
Safety Island
汽车智驾系统,需要满足业界的各种安全标准,即功能安全(ISO 26262),预期功能安全(ISO 21448),信息安全(ISO 21434),对整个系统的安全提出了很高的要求,因此,除了实现功能本身外,还需要对系统各个模块提供实时监控、故障检测、安全通信,为安全策略的执行提供可能性。
但一般集成在SoC中,用于实现功能软件的CPU以及GPU等硬件单元,不管是从硬件设计要求还是底层操作系统,软件开发来看,都无法满足安全标准的要求,或者说如果全部以相应的ASIL等级开发的话,硬件实现的成本以及额外的软件开发要求成本都会过高。
那么,这个问题怎么解决呢? 怎么保证SoC芯片整体的安全性呢?
安全岛的概念由此诞生!为了实现较高的安全性,安全岛必须和SoC其余硬件部分隔离开,形成单独的一个区域,这就好像大海中间一个独立的岛屿,所以安全岛的名称由此而来。
根据解决的安全问题不同,目前一般进一步分为功能安全岛和信息安全岛。
-
功能安全岛主要针对 ISO 26262标准设计,旨在解决E/E系统系统性失效和随机硬件失效问题。
例如,功能安全岛提供了冗余和容错机制,确保即使主处理器故障,关键安全功能如紧急制动和避障系统仍然能够正常运行等等。 功能安全岛无非就是将一个具体安全可靠性的,实时性强,独立的控制单元直接集成或者外接到 SoC 中,本质上就是一颗车规级嵌入式高安全级别要求的MCU(例如,ASIL D)。这样做的好处在于,在保证系统安全的同时,也降低了其他模块安全设计的需求。
-
信息安全岛主要针对 ISO 21434标准,旨在确保汽车系统和软件的安全性,以防止潜在的信息安全漏洞和攻击,保护车辆用户的隐私和安全。 例如,信息安全岛负责执行安全启动过程,验证固件的完整性和真实性,防止恶意软件注入,以及自动驾驶系统需要与外部环境进行大量数据交换,如车联网(V2X)通信,需要确保数据传输的完整性和保密性,防止数据篡改和攻击等等。
信息安全岛和功能安全岛一般独立存在,但二者之间设有专门的安全通信通道,以保证二者协同工作。
MAC
The MAC unit performs multiply-accumulate operations that are required for convolution, depth-wise pooling, vector products, and the max operation required for max pooling.
NPU 中主要是 MAC 单元,MAC 单元的多少决定 NPU 的算力。

PendSV
PendSV 是可悬起异常,如果我们把它配置最低优先级,那么如果同时有多个异常被触发,它会在其他异常执行完毕后再执行,而且任何异常都可以中断它。
RTOS 为什么使用它来进行进程上下文切换呢?
例如,一个系统中有两个就绪的任务,上下文切换被触发的场合可以是:
- 执行一个系统调用;
- 系统滴答定时器(SYSTICK)中断,(轮转调度中需要);
让我们举个简单的例子来辅助理解。假设有这么一个系统,里面有两个就绪的任务,并且通过 SysTick 异常启动上下文切换。但若在产生 SysTick 异常时正在响应一个中断,则 SysTick 异常会抢占其 ISR。在这种情况下,OS 是不能执行上下文切换的,否则将使中断请求被延迟,而且在真实系统中延迟时间还往往不可预知——任何有一丁点实时要求的系统都决不能容忍这种事。因此,在 CM3 中也是严禁没商量——如果 OS 在某中断活跃时尝试切入线程模式,将触犯用法 fault 异常。
为解决此问题,早期的 OS 大多会检测当前是否有中断在活跃中,只有在无任何中断需要响应时,才执行上下文切换(切换期间无法响应中断)。然而,这种方法的弊端在于,它可以把任务切换动作拖延很久(因为如果抢占了 IRQ,则本次 SysTick 在执行后不得作上下文切换,只能等待下一次 SysTick 异常),尤其是当某中断源的频率和 SysTick 异常的频率比较接近时,会发生“共振”, 使上下文切换迟迟不能进行。
现在好了,PendSV 来完美解决这个问题了。PendSV 异常会自动延迟上下文切换的请求,直到其它的 ISR 都完成了处理后才放行。为实现这个机制,需要把 PendSV 编程为最低优先级的异常。如果 OS 检测到某 IRQ 正在活动并且被 SysTick 抢占,它将悬起一个 PendSV 异常,以便缓期执行上下文切换,上下文切换需要做的操作就放在 PendSV 回调函数。
hungtask 机制
hung task 机制用于检测系统中是否存在处于 D 状态超过 120s(时长可以设置)的进程,如果存在,则打印相关警告和进程堆栈。如果配置了 hung_task_panic(proc 或内核启动参数),则直接发起 panic,结合 kdump 可以搜集到 vmcore。从内核的角度看,如果有进程处于 D 状态的时间超过了 120s,那肯定已经出现异常了,以此机制来收集相关的异常信息,用于分析定位问题。
hung task 机制的实现很简单,其基本原理为:创建一个内核线程(khungtaskd),定期(120s)唤醒后,遍历系统中的所有进程,检查是否存在处于 D 状态超过120s(时长可以设置)的进程,如果存在,则打印相关警告和进程堆栈。如果配置了 hung_task_panic(proc 或内核启动参数),则直接发起 panic。
GPGPU
难点:高算力的 GPGPU 芯片,底层硬件如同迷宫,设计和生产的要求十分复杂、专业和苛刻。GPGPU 芯片上会放很多运算单元,让这些运算单元最适当组合并拥有最高的运算效率实现难度极大,一个部分计算单位效率不佳,对整个芯片的影响将放大上千倍。
Lidar/Radar
激光雷达(Lidar, Light Detection and Ranging)是一种光学遥感技术,通过向目标照射一束光,通常是一束脉冲激光,来测量目标的距离等参数。
毫米波雷达(Radar, Radio Detection and Ranging)使用无线电波来探测和测量。
总的来说,Lidar具有优异的方位分辨率,能够精确地检测到与周围障碍物的距离和位置关系,并能实时检测到具有低无线电波反射率的物体 (标志,树木等);Radar 的无线电波比 Lidar 的激光波长,其返回的物体图像不如 Lidar 精确,但它覆盖远距离、具有强穿透性,可在雨,雪,尘土等恶劣环境中返回信息,在夜间和阴天比 Lidar 更准确。
Lidar 比 Radar 更贵。
TBox
T-BOX,无线网关,通过 4G 远程无线通讯、GPS 卫星定位、加速度传感和 CAN 通讯等功能,为整车提供远程通讯接口。提供包括行车数据采集、行驶轨迹记录、车辆故障监控、车辆远程查询和控制(开闭锁、空调控制、车窗控制、发送机扭矩限制、发动机启停)、驾驶行为分析、4G 无线热点分享等服务。
sizeof/strlen
sizeof() 和 strlen() 的主要区别在于:
sizeof()是一个运算符,而strlen()是一个函数。sizeof()计算的是变量或类型所占用的内存字节数,而strlen()计算的是字符串中字符的个数。sizeof()可以用于任何类型的数据,而strlen()只能用于以空字符 ‘\0’ 结尾的字符串。- sizeof() 计算字符串的长度,包含末尾的 ‘\0’,strlen() 计算字符串的长度,不包含字符串末尾的 ‘\0’。
‘\0’
表示字符串结束,不加的话可能会出现乱码,在使用过程中要为其分配内存空间,但不计入字符串长度。
ARM LR/PC
r14: 连接寄存器,也称为 lr 寄存器。LR 寄存器是 ARM 中的链接寄存器,程序跳转(子程序调用,中断跳转)后,arm 自动在该寄存器中存入原程序(未跳转)的下一条指令的地址,也叫函数调用返回地址。当一个函数被调用时,LR 寄存器会存储调用该函数的下一条指令的地址,当函数执行完毕后,程序会跳转到 LR 寄存器中存储的地址继续执行。
r15: 程序计数器,也称为 pc 寄存器。保存的是当前正在取指的指令的地址(arm 采用 2 级流水线,因此是当前正在执行指令的地址 +8)。PC 寄存器是 ARM 中的程序计数器,用于存储下一条将要执行的指令的地址。在程序执行过程中,PC 寄存器的值会不断变化,指向下一条将要执行的指令的地址。当程序执行完毕时,PC 寄存器的值会指向程序的结束地址。
DDR 交织
为了提高 DIMM 的吞吐量,同一颗 IC 内的各个 BANK,被设计成可完全独立工作,可单独访问(即 CPU 访问颗粒以 BANK 为基本单位),也就是说,各个 BANK 可以处于读写周期的不同阶段。
OCP 协议
OpenCore协议(OCP)是由OCP-IP组织制定的开放核接口标准,旨在提升 IP 核复用性并实现即插即用功能。该协议定义了总线独立、可配置且可扩展的接口规范,通过分层设计将IP核功能与系统接口解耦,支持主从设备间的点对点通信。其接口允许配置数据宽度、突发传输模式及服务质量标识,适配不同总线架构或片上网络互联。
Timing Constraints
在芯片设计(尤其是数字芯片设计)中,时序约束(Timing Constraints) 是一组由设计者定义的、用于指导 EDA(电子设计自动化)工具(如综合、布局布线工具)优化电路性能,并验证电路是否能在指定工作条件(如频率、电压、温度)下稳定运行的规则。其核心目标是确保电路中所有信号的传输延迟满足 “时间要求”,避免因信号到达时间不匹配导致的功能错误(如数据采样错误)。
PLL
PLL(Phase-Locked Loop) 是芯片中的 “时钟魔术师”,通过相位负反馈机制,将一个基准时钟转换成多个不同频率且相位可控的时钟,是现代数字芯片、通信芯片和系统芯片(SoC)的 “心脏”。
Harden
芯片设计中,“柔性设计”(如 RTL 代码、未绑定物理信息的逻辑网表)具有灵活性,但缺乏物理层面的确定性(比如时序、功耗无法精确预测);而 “harden” 的过程,就是通过物理设计、工艺绑定、验证固化,将这类柔性模块转化为 “硬件化” 的电路 —— 其布局、布线、时序、功耗均已固定,可直接集成到芯片中,无需二次设计。
简单来说:Harden = 逻辑功能 + 物理实现 + 工艺适配 + 验证签核,最终输出一个 “即插即用” 的硬件模块。
SPECCPU 和 coremark
- coremark 是时间驱动型的测试程序,即它只会运行固定的时间,然后通过计算该时间内执行的指令数来得出性能分数;
- SPECCPU2017 是工作量驱动型的测试程序,即它执行固定数量的指令,将执行时间除以一台参考计算机的执行时间,结果称为 SPECratio, SPECratio 值越大, 表示性能越好。
激励
芯片设计中的 “激励”,本质是为验证芯片功能是否正确而人为输入的测试信号或数据,相当于给芯片 “发指令、喂数据”,观察其输出是否符合预期。激励的形式由芯片类型和功能决定,主要分为三类:
- 时钟信号:芯片的 “心跳”,用于同步内部电路操作(如 CPU 的时钟频率信号)。
- 数据信号:芯片需要处理的核心信息(如存储芯片的读写数据、图像处理芯片的像素数据)。
- 控制信号:指挥芯片执行特定操作的指令(如 “启动”“停止”“读写使能” 等信号)。
Harvest 特性
在芯片制造中,Harvest 特性指的是通过动态识别并隔离芯片中的部分缺陷区域,将原本因局部故障可能被淘汰的芯片转化为可用产品的技术能力。这一技术可以提升良率。
芯片制造中,即使整体设计正确,局部工艺缺陷(如晶体管短路、金属线断裂)仍可能导致功能失效。Harvest 特性通过以下步骤解决这一问题:
- 缺陷定位:利用自动测试设备(ATE)或内置测试电路(DFT)精准识别故障区域。
- 功能隔离:通过熔断熔丝(Fuse)、软件屏蔽等方式禁用故障模块,保留完好部分的功能。
- 重新分级:将修复后的芯片降级为低端型号(如将八核 CPU 屏蔽两核变为六核),推向细分市场。
典型案例
- Intel 处理器:若某颗 i7 CPU 的两个核心存在缺陷,可通过 Harvest 技术将其降级为 i5 型号,避免整颗芯片报废。
- GPU 芯片:若部分计算单元故障,可屏蔽故障区域后作为入门级显卡销售,提升有效产出。
毛刺
在芯片设计(尤其是数字电路设计)中,毛刺(Glitch) 指的是信号在正常逻辑跳变过程中因信号路径延迟差异导致的短暂、非预期的错误跳变,通常表现为信号在稳定到目标电平前,突然出现一次或多次快速的高低电平翻转(持续时间远小于一个时钟周期)。
毛刺主要出现在组合逻辑电路中(无时钟同步的电路),核心原因是 “信号通过不同路径到达同一节点的时间差”:
-
逻辑路径长度差异:不同输入信号经过的逻辑门数量不同(如一个信号经过 2 级门,另一个经过 5 级门),导致到达输出端的延迟不同步;
-
器件工艺差异:同一批芯片中,不同逻辑门的实际延迟可能因制造工艺偏差(如晶体管尺寸、线宽)略有不同;
-
负载差异:信号驱动的负载(如连接的后续电路数量)不同,会导致信号传输速度不同,加剧延迟差异。
FIFO
FIFO 是进行数据速率匹配和数据缓冲非常好的电路元件。然而,它也有一些缺点:
- 在数据穿越 FIFO 时,路径中的延时更长;
- FIFO 中会用到多个计数器,增大了门电路的规模。
因此,当构造数据路径时,应分析 FIFO 是否是必须选择的。另外,在设计中有多个 FIFO 时,应考虑这些 FIFO 是否可以合并,从而减少 FIFO 的数量。
触发器
-
触发器的本质是“带时钟控制的存储单元”
其由多个逻辑门(如与非门、或非门)组合而成,但其核心区别于组合逻辑的特点是:必须依赖时钟信号(Clock)来控制数据的 “更新” 和 “保持”。
-
触发器的工作原理
D 触发器是芯片设计中最广泛使用的类型(约占触发器总量的 90% 以上),其逻辑符号和工作过程如下:
- 核心引脚
- D(Data):数据输入端(输入要存储的二进制信号,0 或 1);
- CLK(Clock):时钟信号输入端(控制数据更新的 “触发信号”);
- Q:输出端(存储的数据,0 或 1);
- Q’:反向输出端(与 Q 相反,即~Q);
- 部分触发器还会有异步复位(RST) 或置位(SET) 引脚(用于强制将 Q 置为 0 或 1,不依赖时钟)。
-
工作过程(边沿触发机制)
D 触发器的核心是 “边沿触发”(绝大多数芯片设计采用这种方式),即仅在时钟信号的上升沿(从 0→1 的瞬间)或下降沿(从 1→0 的瞬间) 时更新输出,其他时间保持状态不变。
以 “上升沿触发” 为例:
-
时钟为低电平(0)或高电平(1)的稳定阶段:无论 D 端输入如何变化,Q 端始终保持上一次锁存的数据(“保持” 状态);
-
时钟上升沿瞬间:触发器会 “采样” 此时 D 端的输入信号(0 或 1),并将 Q 端更新为与 D 相同的值(“更新” 状态);
-
之后时钟再次进入稳定阶段,Q 端保持新值不变,直到下一个上升沿到来。
-
- 核心引脚
-
触发器的核心作用:支撑时序逻辑与同步设计
触发器是数字电路从 “组合逻辑”(输出仅由当前输入决定,如与门、加法器)升级到 “时序逻辑”(输出与历史状态相关)的关键,具体作用体现在三个层面:
-
数据存储:构成寄存器
单个触发器可存储 1 位二进制数据,多个触发器按位排列(如 32 个、64 个) 就构成了 “寄存器”(Register),用于临时存储数据。
-
例如:CPU 中的通用寄存器(如 x0-x31)就是由触发器组成,用于运算过程中临时存放操作数和结果;
-
芯片接口电路中的 “数据缓冲寄存器”,用于暂存输入 / 输出数据,匹配不同模块的速度差异。
-
-
时序控制:实现同步电路
芯片设计中,“同步设计” 是保证电路稳定的核心原则(即所有模块的动作由同一时钟信号协调),而触发器是同步设计的 “执行单元”:
-
组合逻辑(如加法器、解码器)的输出可能存在毛刺(瞬时错误),但触发器仅在时钟边沿采样,可过滤毛刺(因为毛刺持续时间远短于时钟周期,不会被采样到);
-
不同模块通过触发器 “对齐” 时钟节拍,避免因信号传输延迟导致的逻辑混乱(例如:CPU 的取指、译码、执行阶段通过触发器按时钟周期依次推进)。
-
-
构建复杂时序逻辑电路
基于触发器的 “存储 + 时钟触发” 特性,可组合出计数器、移位寄存器、状态机等核心电路:
-
计数器:多个触发器级联,每当时钟触发时状态按规律递增 / 递减(如从 000→001→010…),用于计时、地址生成等;
-
移位寄存器:触发器按顺序连接,数据在时钟触发下逐位移动(如串行数据转并行、加密算法中的位操作);
-
状态机:由触发器存储 “当前状态”,结合组合逻辑判断 “下一状态”,实现复杂流程控制(如芯片的启动流程、通信协议的握手逻辑)。
-
-
-
触发器与锁存器(Latch)的区别
容易混淆的是 “锁存器”,二者都能存储数据,但核心差异在于控制方式:
-
触发器:仅在时钟的边沿(上升沿 / 下降沿)更新状态(“边沿触发”),抗干扰能力强,是同步电路的首选;
-
锁存器:在时钟的电平阶段(如高电平期间)更新状态(“电平触发”),若输入信号在电平阶段波动,输出会跟随变化,易受毛刺影响,主要用于特定场景(如异步接口、低功耗设计)。
-
制程与频率
芯片制程越先进(纳米数越小),理论上最大频率上限越高,但受架构、功耗等约束并非绝对线性提升。
核心影响逻辑
-
晶体管开关速度提升:先进制程让晶体管栅长、沟道长度缩短,电流通过路径更短,开关响应速度更快,为高频运行打下基础;
-
功耗与发热控制优化:更小的晶体管漏电流更低,同等频率下功耗密度下降,可通过提高电压进一步推高频率,同时避免过热触发降频;
-
信号延迟减少:制程先进带来更高晶体管密度,关键运算路径的布线距离缩短,信号传输延迟降低,减少高频下的时序错误。
关键约束条件
- 频率提升受限于电压阈值,过高电压会导致功耗呈指数增长,突破散热极限;
- 先进制程的晶体管驱动能力可能减弱,需通过架构设计(如多栅极结构)补偿;
- 芯片最大频率是制程、架构、电压、散热的综合结果,并非制程越先进就一定频率越高。
哪些因素限制了 cache 的增大
-
芯片面积成本(最主要因素)
┌─────────────────────────────────────────────────────────────┐ │ 芯片面积分配示意图 │ │ │ │ ┌─────────────────────────────────────────────────────┐ │ │ │ │ │ │ │ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ │ │ │ │ │Core0│ │Core1│ │Core2│ │Core3│ CPU 核心 │ │ │ │ └─────┘ └─────┘ └─────┘ └─────┘ (~30%) │ │ │ │ │ │ │ │ ┌───────────────────────────────────────────┐ │ │ │ │ │ │ │ │ │ │ │ L2/L3 Cache │ │ │ │ │ │ (~40-50%) ← 占比最大! │ │ │ │ │ │ │ │ │ │ │ └───────────────────────────────────────────┘ │ │ │ │ │ │ │ │ ┌─────────────┐ ┌─────────────┐ │ │ │ │ │ 内存控制器 │ │ I/O 接口 │ 其他 (~20%) │ │ │ │ └─────────────┘ └─────────────┘ │ │ │ └─────────────────────────────────────────────────────┘ │ └─────────────────────────────────────────────────────────────┘-
Cache 面积 ∝ 容量:每增加 1MB SRAM 需要约 1-3 mm²(取决于工艺);
-
7nm 工艺:1MB SRAM ≈ 1.5 mm²;
-
4nm 工艺:1MB SRAM ≈ 0.8 mm²;
-
Thor-U 能用 1MB L2 的原因:4nm 工艺密度更高!
-
访问延迟(Cache 越大越慢)
Cache 大小 vs 访问延迟的权衡: 延迟 (cycles) │ 12├─────────────────────────────────────●──── 8MB L3 │ ● 10├─────────────────────────────────●─────── 4MB L3 │ ● 8├───────────────────────────●───────────── 2MB L3 │ 6├─────────────────●─────────────────────── 1MB L2 │ ● 4├───────────●───────────────────────────── 512KB L2 │ ● 2├───●─●─●───────────────────────────────── 256KB L2 │ ● 1├●──────────────────────────────────────── 32KB L1 └──┬───┬───┬───┬───┬───┬───┬───┬───┬───→ 容量 32K 64K 128K 256K 512K 1M 2M 4M 8M-
更大的 Cache 需要更多的寻址逻辑;
-
更长的物理走线距离;
-
更复杂的Tag 比较电路;
典型延迟:
Cache 级别 大小 延迟 L1 32-64 KB 1-4 cycles L2 256KB-1MB 10-20 cycles L3 4-32 MB 30-50 cycles -
Orin-X 用 256KB L2 的考量:保证更低的 L2 访问延迟
-
功耗(静态 + 动态)
Cache 功耗 = 静态功耗(漏电流)+ 动态功耗(读写) ┌──────────────────────────────────────────────────────────┐ │ 功耗 │ │ (W) │ │ │ │ │ 3 ├─────────────────────────────────────●─ 动态功耗 │ │ │ ● │ │ 2 ├────────────────────────────●──●─────── │ │ │ ● │ │ 1 ├──────────────────●───●───────────────── 静态功耗 │ │ │ ●──●── │ │ │ ●──●── │ │ └──┬───┬───┬───┬───┬───┬───┬───→ Cache 大小 │ │ 256K 512K 1M 2M 4M 8M 16M │ └──────────────────────────────────────────────────────────┘-
静态功耗(漏电流):
-
SRAM 单元即使不工作也在漏电;
-
Cache 越大,漏电流越大;
-
在移动/嵌入式场景尤其重要;
-
-
动态功耗:
-
每次读写都消耗能量;
-
大 Cache 需要驱动更多的位线和字线;
-
-
-
制造良率
芯片良率 vs Cache 面积: 良率 (%) │ 95├●─●────────────────────────────────────── │ ●──● 90├────────●──●───────────────────────────── 小芯片 │ ● 85├────────────●──●──────────────────────── │ ● 80├─────────────────●─────────────────────── 中等芯片 │ ● 70├───────────────────●───────────────────── │ ● 60├─────────────────────●─●───────────────── 大芯片 │ ● 50├───────────────────────────●──●────────── 超大芯片 └──┬───┬───┬───┬───┬───┬───┬───┬───→ 芯片面积 50 100 150 200 300 400 500 600 (mm²)Cache 越大 → 面积越大 → 良率越低 → 成本越高
-
设计复杂度
| 挑战 | 说明 |
|---|---|
| 一致性协议 | Cache 越大,需要追踪的缓存行越多,Snoop Filter/Directory 越复杂 |
| 替换策略 | 大 Cache 的 LRU 等替换算法开销更大 |
| ECC 校验 | 更多的存储位需要更多的 ECC 位(约 12.5% 开销) |
| 电源管理 | 需要细粒度的 power gating 来关闭不用的 Cache bank |
-
收益递减效应
性能提升 (%) │ 50├●───────────────────────────────────────── │ ● 40├──●────────────────────────────────────── 收益快速增长 │ ● 30├────●───────────────────────────────────── │ ● 20├──────●────●───────────────────────────── 收益递减 │ ●───● 10├────────────────●───●───●───●──────────── 边际收益很小 │ ●───●───● 0├────────────────────────────────────●─●── 工作集完全装入 └──┬───┬───┬───┬───┬───┬───┬───┬───┬───→ Cache 大小 256K 512K 1M 2M 4M 8M 16M 32M 64M原理:
-
小 Cache → 大 Cache:大量 Miss 变成 Hit,收益大;
-
大 Cache → 更大 Cache:已经是 Hit 的不会更快,收益小;
-
工作集完全装入后,再增大 Cache 完全没有意义;
-
Split-lock 模式
Split-Lock 模式本质是 ARM 处理器核心的双模式运行机制,通过硬件配置让处理器簇(Cluster)中的核心在 “独立高性能运行” 和 “冗余安全运行” 之间切换,核心解决汽车等场景中 “同一硬件需支撑多安全等级任务” 的痛点:
- 无需为非安全任务(如车载娱乐)和安全任务(如紧急制动控制)分别设计硬件,降低 SoC 复杂度与成本;
- 兼顾性能与安全:非安全场景追求算力,安全场景确保故障无感知冗余;
- 支持故障降级:即使部分核心故障,系统仍能以 “降级模式” 继续运行,而非直接瘫痪。
Split-Lock 的三种运行模式
ARM Split-Lock 技术包含Split 模式、Lock 模式和后续扩展的Hybrid 模式,三种模式针对不同安全等级与性能需求设计,可通过系统启动配置或动态切换(部分场景)实现。
-
Split 模式:追求高性能,适用于非安全关键任务
-
核心机制
-
处理器簇中的核心完全独立运行(如 2 个核心分别处理导航、音乐播放),无冗余执行;
-
核心可灵活分配给不同任务,充分释放算力,最大化单核心 / 多核心性能;
-
不启用硬件冗余检查,仅满足基础可靠性,无额外安全开销。
-
-
适用场景与安全等级
-
非安全关键任务:车载信息娱乐(IVI,如音乐、导航、座舱温控)、车载通信(如 5G / 蓝牙数据传输);
-
安全等级:符合ASIL B/SIL 2(中等安全需求,故障影响局限于局部,无生命危险);
-
典型用例:车辆正常行驶时,Split 模式下的核心分别处理 4K 视频播放、实时导航地图渲染,确保用户体验流畅(摘要 3、4、6)。
-
-
-
Lock 模式:硬件冗余,适用于最高安全关键任务
-
核心机制
-
处理器簇中的核心两两配对,同步锁步运行(如 2 个核心执行完全相同的代码,输出完全一致的结果);
-
搭配 ARM Dynamiq 共享单元(DSU,含共享缓存与一致性逻辑)也运行在锁步模式,确保 “核心 + 共享资源” 的全链路冗余;
-
硬件实时监控配对核心的执行结果:若出现任何指令、数据或时序差异,立即触发错误报告,由故障恢复机制接管(如切换到备用核心、通知系统降级)。
-
-
适用场景与安全等级
-
安全关键任务:ADAS L2 + 功能(如高速自动避险、紧急制动、车道保持)、自动驾驶决策系统;
-
安全等级:符合ASIL D/SIL 3(最高安全需求,故障可能导致生命危险,需 “故障无感知” 冗余);
-
典型用例:车辆在浓雾中行驶时,Lock 模式下的核心对同步处理激光雷达 / 摄像头的障碍物数据,计算避险路径,确保任何单一核心故障都不会导致系统失效。
-
-
-
Hybrid 模式:平衡安全与性能,适用于中等安全需求
-
核心机制
-
核心层面:部分核心独立运行(Split 模式,处理非安全任务);
-
共享资源层面:仅 DSU(Dynamiq 共享单元)运行在 Lock 模式,确保核心间数据一致性与基础冗余;
-
无需全核心锁步,既降低安全开销,又满足中等安全需求的冗余要求。
-
-
适用场景与安全等级
-
中等安全任务:如自适应巡航(ACC)、盲区监测(BSD);
-
安全等级:符合ASIL B/SIL 2,且相比纯 Split 模式有更高的故障覆盖率,同时减少测试 downtime。
-
-
A4S 接口
A4S 是AXI4-Stream的简称,是 ARM 公司 AMBA(高级微控制器总线架构)总线家族中专门为高速数据流传输设计的接口协议,核心定位是 “无地址映射的连续数据传输通道”,与用于内存映射的 AXI4、AXI4-Lite 形成功能互补,广泛应用于视频处理、网络通信、FPGA 高速数据交互等场景。
从 AMBA 总线家族的功能分工来看,A4S 与其他 AXI 类型的定位差异明确:
- AXI4:高性能内存映射总线(如 CPU 访问 DDR),支持最多 256 个事务的突发传输;
- AXI4-Lite:轻量版内存映射总线(如 CPU 读写 UART/GPIO 寄存器),仅支持 1 个事务的突发传输,适用于低速低吞吐量场景;
- A4S(AXI4-Stream):无地址的高速流数据总线(如视频帧、网络数据包传输),支持无限长度的突发传输,专注于 “高带宽、低延迟” 的连续数据交互。
异步桥
芯片中存在大量 “异步时钟域”(如 CPU 核心用 2GHz 时钟,UART 外设用 115.2KHz 时钟,PCIe 接口用 16GHz 时钟),若直接跨时钟域传输信号,会因 “采样时钟与信号跳变不同步” 导致两大问题:
-
亚稳态:信号在采样时钟的 “建立 / 保持时间窗口” 内跳变,导致接收端触发器输出在 0 和 1 之间振荡,无法稳定,进而引发系统逻辑错误;
-
数据一致性破坏:多比特信号(如 32 位数据总线)跨域时,各比特到达时间不同(总线偏移),导致接收端采样到 “半旧半新” 的数据(数据撕裂)。
异步桥的设计初衷就是通过硬件级同步机制,在不依赖软件干预的前提下,解决上述问题,实现 “异步时钟域间的可靠通信”,同时避免不同时钟域的时序约束相互干扰。
vip
IP(Verification IP)是预封装、可重用、符合行业标准协议的验证组件,核心目标是替代工程师手动编写协议相关的验证代码,高效验证芯片的接口 / 模块(如 AHB/AXI 总线、I2C/SPI 外设、PCIe 等)。
简单来说,VIP 的工作本质是:
- 模拟协议的 “发起方”(如 AHB Master)或 “响应方”(如 AHB Slave),向被测设计(DUT)产生合规的激励;
- 实时监测总线信号,解析协议行为,检查 DUT 是否符合协议规范;
- 对比 “预期结果” 和 “实际结果”,自动输出验证报告。
IP 的 OT/BLEN/Burst
Burst(突发传输)
-
定义:主机只发一次地址 / 命令,连续传输一整段地址连续的数据,中间不释放总线。
-
它衡量什么?
-
IP 是否支持高效批量传输
-
是高速传输的基础机制,没有 Burst 就没有高性能
-
-
为什么重要?
地址 / 命令的开销很高,如果每个数据都发一次地址,总线利用率极低。只有支持 Burst,才能谈 BLEN、OT。
-
影响最显著的场景:
- 所有高速数据通路:DDR、PCIe、以太网、视频传输、NPU/GPU 访存。
- 低速外设(I2C/SPI/UART)基本不用 Burst。
BLEN(Burst Length):突发长度
-
定义:一次 Burst 传输多少拍 / 多少字节。例如 AXI:1/4/8/16 beat;DDR:BL2/4/8/16。
-
它衡量什么?
-
单次传输的效率
-
命令开销占比
- BLEN 越大:命令开销越低,总线利用率越高
- BLEN 越小:开销越大,但响应快、不阻塞别人
-
-
优点:BLEN ↑ → 总线效率 ↑,极限带宽 ↑
-
缺点:BLEN ↑ → 单次占用总线时间变长 → 其他主机容易饥饿、时延变大
-
影响最显著的场景:
-
大块连续数据:视频帧、图像、DMA 搬移、DDR 读写
-
小数据包、控制指令:反而要用短 BLEN
-
OT(Outstanding Transactions): outstanding 未完成请求数
这是三者里最核心、最决定性能的指标。
-
定义:主机发一个请求后,不等对方返回响应 / 数据,就可以发下一个请求。OT = 最大允许同时 “在路上” 的请求数量。
-
它衡量什么?
-
IP 的并发能力
-
流水线深度
-
抗长延迟能力(DDR、PCIe、跨时钟域、NoC 延迟都很高)
-
有一个非常关键的实战公式:
实际带宽 ≈ 频率 × 位宽 × OT × 效率
链路延迟越长,OT 对带宽的影响就越大。
-
优点:OT ↑ → 并发↑ → 即使链路延迟高,也能跑满带宽
-
代价:OT ↑ → 必须缓存更多请求 → 面积更大、时序更难、控制逻辑更复杂
-
影响最显著的场景:
-
高延迟链路:DDR、PCIe、Chiplet 互联、NoC、跨时钟域
-
多主机、高并发系统(CPU/NPU/GPU 共享总线)
-
EMU/FPGA
-
FPGA(原型验证)
它是可编程逻辑芯片,把你的 RTL 综合、布局布线、跑真实时钟。
-
优点:频率能跑到几百 MHz,可以跑系统、跑 Linux、跑软件、跑通功能;
-
缺点:和真实芯片的微架构、时序、性能完全对不上;
-
-
EMU(Hardware Emulator 硬件仿真器)
它是专门给芯片做周期精确仿真的大型硬件;
-
优点:100% 保留 RTL 周期行为、微架构、总线、OT、反压、冲突;
-
缺点:运行频率很低(一般 1MHz ~ 50MHz),但性能测的是周期数,不是频率;
-
FPGA 唯一的、不可替代的价值:跑得快,可以:
- 跑操作系统
- 跑固件、驱动、软件
- 做系统联调
- 测功能是否通
- 软件提前开发(芯片还没回片,软件已经写完)
它只管:能不能跑、有没有 BUG、功能对不对;
不管:快不快、带宽多少、延迟多少、OT 满不满、Burst 效率高不高;
FPGA 只改【实现方式 / 速度 / 时序 / 物理层】,完全不改【逻辑功能 / 状态机 / 协议行为 / 数据运算】,功能对不对,只看逻辑,不看用什么硬件实现。比如:
- if/else、case、状态机跳转
- AXI 握手逻辑:valid/ready 什么时候拉高
- 命令解析:读 / 写、Burst 类型、BLEN 计算
- OT 计数器:加 1、减 1、判断是否满
- FIFO 空满、中断、配置寄存器
- 数据计算、比较、跳转
这些叫行为逻辑。FPGA 综合器的原则是:必须和你 RTL 写的逻辑 100% 一样。不一样就是综合工具 BUG,不可能商用。
所以所有逻辑 bug、功能 bug、协议 bug,FPGA 全都能抓到!而 99% 的芯片 bug,都是逻辑 bug、状态机 bug、协议 bug、配置 bug、数据 bug,和频率、时序、物理层、性能无关。
CPU 预测错误时对 load/store 数据的处理机制
现代 CPU 通过以下结构实现推测执行与错误恢复:
| 组件 | 核心功能 | 预测错误时行为 |
|---|---|---|
| ROB (重排序缓冲区) | 按程序顺序保存所有指令执行结果,控制指令提交顺序 | 清除错误分支后的所有条目,恢复到分支前状态 |
| Store Buffer (存储缓冲区) | 暂存未提交的 store 操作,实现写合并与内存重排 | 丢弃错误路径上的 store 条目,不写入内存 / 缓存 |
| Load Buffer (加载缓冲区) | 记录未完成的 load 操作,检测内存顺序冲突 | 标记错误路径上的 load 为无效,清除相关依赖 |
| 寄存器重命名表 | 隔离架构寄存器与物理寄存器,避免 WAR/WAW 冒险 | 恢复到分支前的寄存器映射关系 |
错误处理的完整流程
- 错误检测与流水线冲刷
- 当分支条件计算完成或内存依赖解析后,发现预测错误时,CPU 立即触发流水线冲刷 (squash/flush)
- 停止错误路径上所有指令的执行,标记这些指令为瞬态指令 (transient instructions),它们不会影响最终的架构状态
- 内存操作的隔离与丢弃
- Store 指令:推测执行的 store 仅写入 Store Buffer,不会立即更新缓存或内存。错误时,直接丢弃 Buffer 中对应条目,内存状态保持不变
- Load 指令:推测执行的 load 可能读取缓存或 Store Buffer 中的数据,但结果仅暂存于物理寄存器和 Load Buffer。错误时,清除这些临时数据,相关依赖指令也被标记为无效
- 状态恢复与重新执行
- ROB 回滚:将 ROB 尾指针重置到错误分支指令位置,保留分支前已完成且正确的指令
- 寄存器状态恢复:通过寄存器重命名表,恢复到分支前的架构寄存器状态
- 重新取指:从正确的分支目标地址开始重新取指、解码和执行
内存一致性保障机制
CPU 通过以下规则确保内存操作的正确性,即使在推测执行时:
- Store 提交顺序:Store 指令仅在 ROB 头部且确认无错误时,才会提交到内存系统,保证按程序顺序写入
- 内存依赖检测:Load 执行时会检查所有更早的 Store 地址,若存在冲突 (RAW 冒险) 则等待 Store 完成
- 内存顺序冲突处理:若检测到推测 Load 读取了错误数据,会标记该 Load 为 “violated”,在退休时触发流水线刷新并重新执行
CPU 预测错误时对 load/store 数据的处理核心原则是:推测执行的内存操作不会修改最终的架构状态,所有临时结果都被隔离在专用缓冲区中,错误时通过 ROB 和寄存器重命名机制原子性回滚,确保程序执行的正确性和可预测性。
the pre-commit stage
Pre-commit stage(预提交阶段) 是现代乱序执行 CPU 中,指令完成执行后到正式提交(commit/retire)前的关键阶段,也常被称为完成(completion)阶段或执行后等待(post-execution waiting)阶段。这个阶段是 CPU 实现推测执行安全回滚与精确异常处理的核心环节,所有指令必须在此等待直到确认无错误,才能最终修改架构状态。
ROB and Rename unit
寄存器重命名:把 ISA 架构寄存器(程序员看见的少量寄存器)映射成 CPU 内部大量物理寄存器,消灭 WAR/WAW 伪依赖,让指令能真正乱序并行。
ROB 重排序缓冲区:严格守住程序原始顺序,负责:顺序退休、精确异常、分支预测失败整机状态回滚、隔离推测执行。
两者绑定强耦合:Rename 负责 “拆依赖、乱序跑”,ROB 负责 “保顺序、可回滚、安全提交”。
【IF 取指】
↓
【ID 解码】 拆出:源架构寄存器、目的架构寄存器、操作码
↓
【Rename 重命名单元】
1. 查 RAT:把 架构寄存器 → 物理寄存器
2. 给目的寄存器 分配全新空闲 PR
3. 更新 RAT 映射表
4. 拍一张【当前RAT快照】备用回滚
↓
【分配 ROB 条目】
1. 每条指令占1个ROB槽,按程序指令顺序入队
2. ROB 保存:PC、源PR/目的PR、RAT快照、执行状态、异常标记
3. 绑定 LB/SB 条目(若是Load/Store)
↓
【RS 保留站 入队】
等待源操作数就绪,可乱序、不按程序序
↓
【EX 乱序执行】
ALU运算 / LSU访存(Load读缓存、Store只进SB)
↓
【写回 PRF】
运算/Load结果 写入 物理寄存器PRF
标记对应 ROB 条目为「执行完成」
↓
【Pre-Commit 预提交】
指令已做完,但仍在ROB里排队、可回滚
不修改ARF、不真正写内存
↓
【ROB 顺序退休 Retire】
从ROB头部按程序顺序逐条提交
1. 把PRF结果写入 ARF 架构寄存器
2. Store从SB真正写入Cache/内存
3. 回收空闲物理寄存器、释放ROB/LB/SB条目
how to resteer
- 分支预测错了,发现要冲刷流水线;
- CPU 直接拿出分支指令对应的 ROB 条目里保存的 RAT 快照;
- 用快照直接覆盖整个 RAT 映射表 → 寄存器重命名状态瞬间回到分支前;
- 清空 ROB 中该分支之后所有条目、清空保留站 RS、清空 LoadBuffer/StoreBuffer;
- 所有错误推测执行的指令:
- 物理寄存器临时结果直接废弃;
- 从没改过 ARF 架构寄存器;
- Store 从没进 Cache / 内存;
整机架构状态完全回滚,仿佛错误路径从没执行过